We are back at the bakery, similar to the one that Poincaré visited. In that blog post we looked at the story of the baker and how he came to some conclusion regarding risks. In this blog post we are going to take a closer look at statistical inference and especially confidence intervals so let's get to it.
Imagine this situation: you are the quality assurance manager at the bakery which you think is a nice (and quite easy) job. One day the big bakery boss comes to you and says:
There has been some complaints about the weight of our breads... I want to know things about the weight of the breads we are producing.... now!
Oh shoot.... I thought things were going smooth... But, the boss wants to know some stuff about the weight of the breads that we are producing... that can't be that hard, or can it?
First of all, I guess that he wants to know stuff about the breads that we are going to produce in the near future and that is a LOT of breads. What if we measure all of the breads, say for the coming weeks, and then give him a list of all the individual weight. It will be a very long list and I don't think that the boss will like this way of presenting data.
Summary statistics
I guess that we can use all the measured breads and calculate some summary value (we will call it a summary statistic from here on) and then present that to the boss. Perhaps the mean (average) weight of all the measured breads will be of interest to him. Let's make a drawing of this

The group of all breads will be called the population from here on. Nice we are all done! Measure all the breads (the population) and calculate a summary statistic (e.g. the mean) and present it to the boss, no problem! Or perhaps there is... I realize now that it will not be possible to measure all the breads, it will take very long time and cost a lot of money. Looking at the budget, it is only possible to measure a very tiny fraction of all the breads. Hmmm can this still be useful? Why don't we measure a number of breads, referred to as a sample, apply the summary statistics that we are interested in to the sample and say that this is an estimate of the summary statistics for the population (all breads). Problem solved! Let's include this is the drawing.
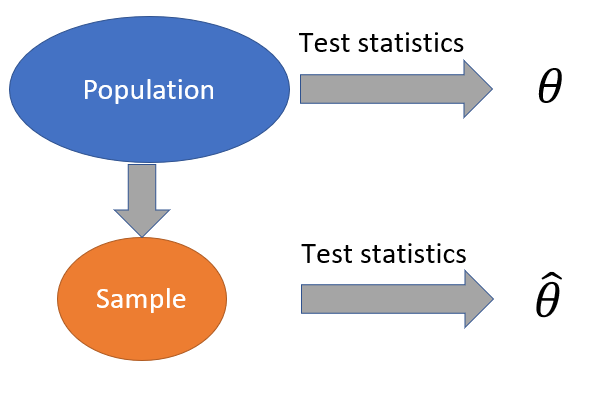
Well there is one good thing and one bad thing about this approach:
- The good thing is that calculating the summary statistics \(\hat{\theta}\) using the sample is indeed the best estimate of the summary statistics \(\theta\) of the population (all breads) .
- The bad thing is that even though it is the best estimate we can get, it can still be a lousy estimate. How bad can it be...?
Let's fire up a jupyter notebook and do some simulations.
Let's start of with a situation where we have measured all the breads so we can compute the true test statistic for the population. This is of course not realistic as discussed above but simulation give you these kind of (super) powers. We will come back to this later and sort of undo this assumption. So, let's generate some data and plot it.
population = np.random.normal(loc=1000,scale=50,size=100000) plt.figure(figsize=(10,7)) plt.hist(population,bins=50,color='b',edgecolor='k') plt.xlabel('Weight [g]') plt.show()
And the histogram
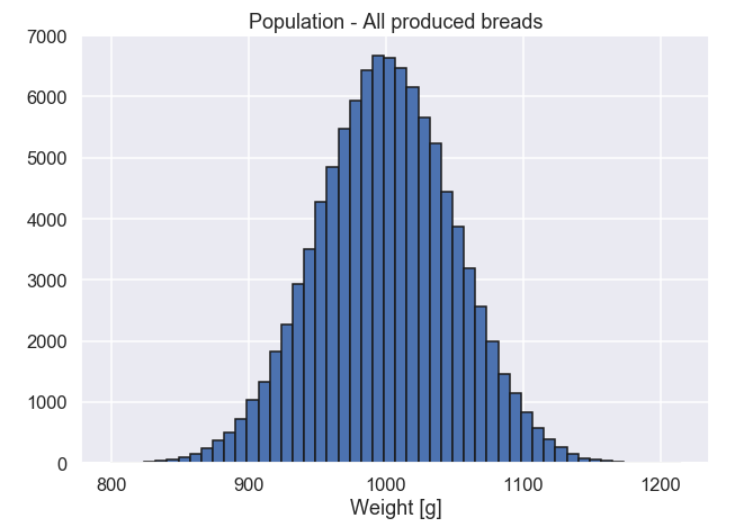
Now, Let's calculate a test statistic for the whole population, here we look at the mean
true_mean = np.mean(population) true_mean

So the true value if the mean is very close to 1000 g. So, let's get into the interesting part. As said above we can not afford to measure all the breads, we can only measure a small fraction of the total number of produced breads. A sample can be viewed as a small number of breads (in this case 25) taken at random from the whole population of breads. Let's do this by using the numpy function random.choice:
Sample = np.random.choice(population,size=25,replace=False)
Let's run this a couple of times and plot the histogram of the sample as well as calculate the mean value of the sample (this is our estimate of the true mean)
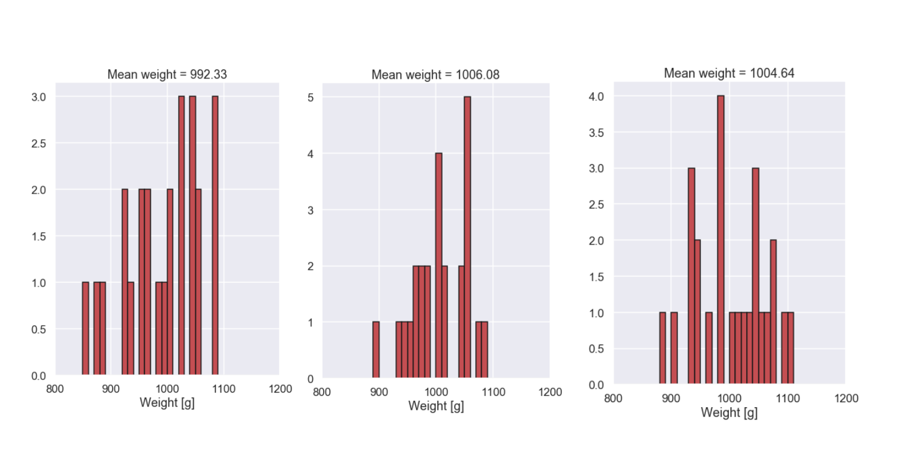
I guess that you see the point here, if we look at different samples of the same size (in this case 25 breads) the mean value will not be identical. From the three different samples we have looked at above it seems that the sample mean can differ close to 10 g from the true mean. So something interesting would be to keep on taking different samples of size 25 and calculate the sample mean and do this a lot of times, say 10 000. Then make a histogram to investigate the different samples mean values, let's do this!
Sampling_distribution_mean = [] for ii in range(0,10000): Sample = np.random.choice(population,size=25,replace=False) Sampling_distribution_mean.append(np.mean(Sample)) Sampling_distribution_mean = np.array(Sampling_distribution_mean) plt.figure(figsize=(10,8)) plt.hist(Sampling_distribution_mean ,bins=np.arange(950,1050,2),color='r',edgecolor='k') plt.xlim(950,1050) plt.title('Sampling Distribution of the mean') plt.xlabel('Mean weight of 25 breads [g]') plt.show()
And the histogram
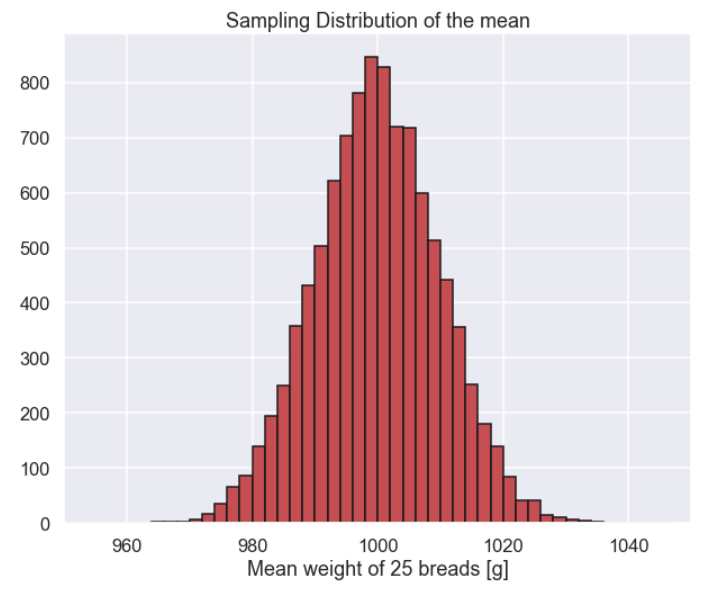
So, this is called the sampling distribution of the mean and what can we say about it? Well, first of all it should be clear that the variation that we see in the graph above is just due to sampling, no other source of variation, such as measurement errors, is present. It seems that the most common value of the sample mean is very close to the true mean. Moreover, most of the mean values seems to be within 980g to 1020g. Then there were these crazy occasions when we got a mean value of the sample that was above 1040g or below 960 but that just happened a few times. So, the histogram above is very informative, I would say, but is there a way to summarize it in some numbers?
The most common way is probably to present an interval that contain for instance 90% of the values. This can be done by chopping off 5% of the lowest values and 5% of the highest values to get a 90% Confidence Interval. Let's do this using the numpy.percentile function
CI_low = np.percentile(Sampling_distribution_mean,5) CI_high = np.percentile(Sampling_distribution_mean,95) print('Confidence interval low = ' + str(np.round(CI_low,2))) print('Confidence interval high = ' + str(np.round(CI_high,2)))

So if we took a sample of 25 breads from the population and calculated the mean for the sample we would be pretty sure that it would be between 984g and 1016g. So if we instead took sample of the size 50 breads, what would happen to the confidence interval? Let's try that out as well
Sampling_distribution_mean_50 = [] for ii in range(0,10000): Sample = np.random.choice(population,size=50,replace=False) Sampling_distribution_mean_50.append(np.mean(Sample)) Sampling_distribution_mean_50 = np.array(Sampling_distribution_mean_50) plt.figure(figsize=(10,8)) plt.hist(Sampling_distribution_mean_50 ,bins=np.arange(950,1050,2),color='orange',edgecolor='k') plt.xlim(950,1050) plt.title('Sampling Distribution of the mean') plt.xlabel('Mean weight of 50 breads [g]') plt.show()
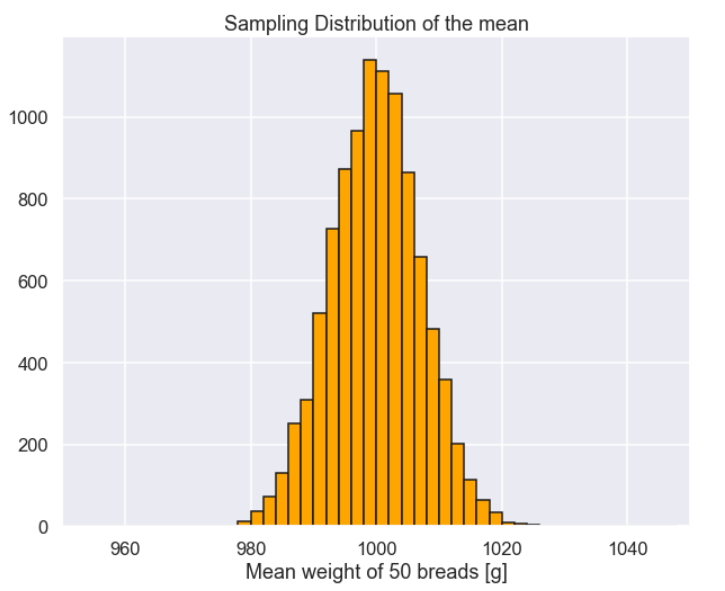
CI_low = np.percentile(Sampling_distribution_mean_50,5) CI_high = np.percentile(Sampling_distribution_mean_50,95) print('Confidence interval low = ' + str(np.round(CI_low,2))) print('Confidence interval high = ' + str(np.round(CI_high,2)))

So the confidence interval will be smaller if the sample size increases. The width of the confidence interval will keep on decreasing as the sample size increases and in the limit, where the sample is the same size as the population, we will obtain exactly the mean of the population.
Introducing the Bootstrap
The idea was to take a lot of samples of a certain size from the population and investigate how the summary statistic for each sample would vary. Well... we can't really do that can we... Getting back to the fact that we can not afford to measure that many breads... Let's say that we can only measure 25 breads and that is it. This is the point where we will undo the assumption that we know the whole population so from now on we only have the sample.
What can we do then? Well here is a crazy idea: Why don't we pretend that the sample we have of 25 breads is the population! We can calculate the test statistic of the sample with we know is the best estimate we have for the population. Then we can take samples from the sample, know as bootstrap samples, to investigate how much this test statistic may vary! This sounds crazy you might think, if I take a sample of 25 breads from the 25 measured breads it will always be the same breads!! Well, here is the trick, the sampling is done with replacement. So, from the 25 measured breads we draw one bread at random, note the weight and put the bread back again. We then continue doing this until we have 25 weights and then calculate the test statistic, in this case the mean value. This process is then repeated a lot of time similar to what was done above. Let's write some code for this.
First we must take a sample from the population
sample = np.random.choice(population,size=25, replace=False)
and from now on this is the only information we have about the population. Now we calculate the test statistics for the sample, in this case the mean
mean_sample = np.mean(sample) mean_sample

Well our best estimate of the mean for the population would be 997g (remember that we do not know the true value!). Now, let's take a lot of bootstrap samples from the sample and calculate a 90% confidence interval
Bootstrap_means = [] for ii in range(0,10000): Bootstrap_sample = np.random.choice(sample,replace=True,size=(25)) Bootstrap_means.append(np.mean(Bootstrap_sample)) Bootstrap_means = np.array(Bootstrap_means) plt.figure(figsize=(10,7)) plt.hist(Bootstrap_means ,bins=np.arange(950,1050,2),color='r',edgecolor='k') plt.xlim(950,1050) plt.xlabel('Mean weight of 25 breads [g]') plt.title('Bootstrap Sampling distribution of the mean') plt.show()
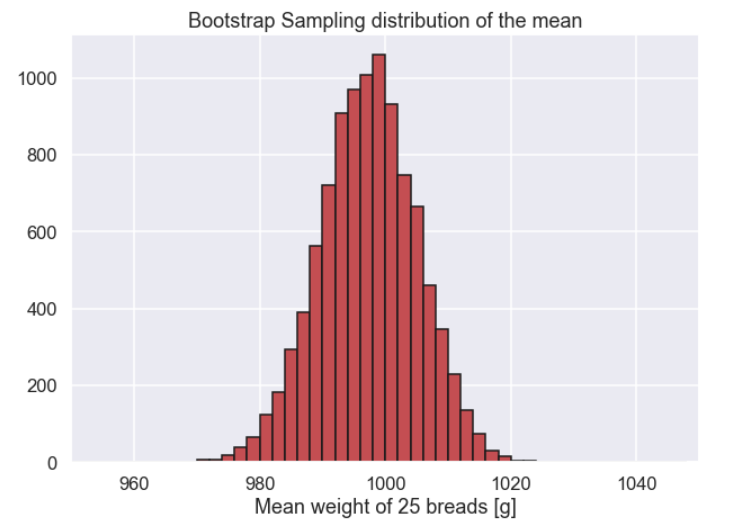
CI_low = np.percentile(Bootstrap_means,5) CI_high = np.percentile(Bootstrap_means,95) print('Confidence interval low = ' + str(np.round(CI_low,2))) print('Confidence interval high = ' + str(np.round(CI_high,2)))

As you can see from the code above the only difference from what we did before is that now we take (bootstrap) samples from the sample using the option replace = True. The replacement will ensure that all the 25 weights are equally likely to be selected each time a bread is drawn from the sample. So the same bread can appear more than once, and some may not appear at all, in a bootstrap sample.
So from the sample we got this time we can say that it is likely that the calculated confidence interval contains the population mean. Just one final thing regarding the confidence interval. If we would take a new sample from the population we would (most likely) get a different value of the sample mean and a different confidence interval. Let's do this procedure many times and, for each sample, record the mean and the confidence interval of the mean.
Mean_list = [] CI_low_list = [] CI_high_list = [] for _ in range(0,1000): # take sample from the population sample_25 = np.random.choice(population,replace=False,size=25) # calculate test statistic for the sample mean_sample_25 = np.mean(sample_25) # take boostrap samples and calculate 90% CI bs_samples_means = np.mean(np.random.choice(sample_25,replace=True,size=(10000,25)), axis=1) bc_ci_low = np.percentile(bs_samples_means,5) bc_ci_high = np.percentile(bs_samples_means,95) # store values Mean_list.append(mean_sample_25) CI_low_list.append(bc_ci_low) CI_high_list.append(bc_ci_high) Mean_list = np.array(Mean_list) CI_low_list = np.array(CI_low_list) CI_high_list = np.array(CI_high_list)
and lets plot the 25 first means and confidence intervals
plt.figure(figsize=(10,10)) for i in range(0,25): plt.plot([CI_low_list[i],CI_high_list[i]],[i,i],'b',lw=2) plt.plot(Mean_list[i],i,'bo') # plot true mean of the population plt.vlines(np.mean(population),-1,25,'k') plt.title('Mean weight and confidence interval') plt.xlabel('Weight [-]') plt.show()
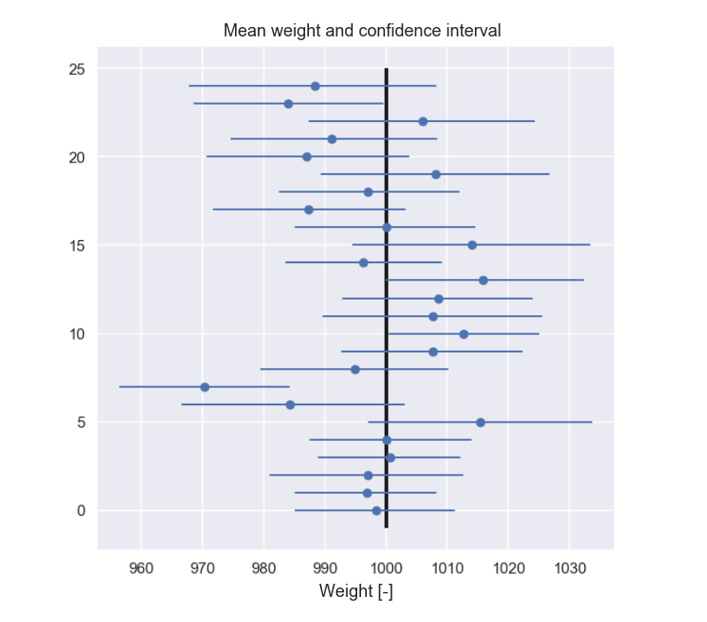
Here we have marked the true population mean with a black line (we are back at knowing the true population mean again, just to understand more of the graph). As can be seen, most of the confidence intervals do contain the true population mean but there are some that do not. Moreover there is a least one that is quite far off. So what we know is that if we follow this procedure of calculating a confidence interval, 90% of the times the confidence interval will contain the true value. But looking at an individual confidence interval, we do not know if this one contains the true mean or not. If we are unlucky we could get the one with a mean just above 970g. Just as a check we calculate how many of the 1000 intervals we just calculated that actually contains the true mean
np.sum( (CI_high_list> np.mean(population) ) & (CI_low_list< np.mean(population)) )

So just below 90%.
Well done so let's go the the boss and tell him what we found out after taking a sample of 25 breads. From this we estimated the mean weight of the whole production of breads together with a 90% confidence interval of the mean. He gets that "that don't impress me much" look and tells you with an evil smile:
I want to know the estimate for the proportion of produced breads that weigh less than 970g along with its corresponding confidence interval
(The boss remember from school that this would be extremely hard to calculate by hand). You respond

The thing is that when using the boostrap approach you can easily change the test statistic, you just need to change one row in the code above, let's try that!
First, we define a function that takes a sample as input and calculates the fraction of breads with a weight below 970g. In this case it is done like this:
- Assume that the weight of the breads can be described by a normal distribution
- Calculate the mean and the standard deviation using the sample
- Use a the cumulative distribution function to calculate the fraction of breads that have a weight below 970 g
def below_970(ss): ss_mean = np.mean(ss) ss_std = np.std(ss) return sp.stats.norm.cdf(970,loc=ss_mean,scale=ss_std)
Now let's run the same bootstrap procedure as above but change the part where we calculate the test statistic so it includes the function we just defined
below_970_estimate = below_970(sample) Bootstrap_below = [] for ii in range(0,10000): Bootstrap_sample = np.random.choice(sample,replace=True,size=(25)) Bootstrap_below.append(below_970(Bootstrap_sample)) Bootstrap_below = np.array(Bootstrap_below) plt.figure(figsize=(10,7)) plt.hist(Bootstrap_below,bins=np.arange(0.0,0.45,0.01),color='g',edgecolor='k') plt.xlim(0,0.45) plt.xlabel('Fraction of breads bekow 970g [-]') plt.title('Bootstrap sampling distribution of the fraction of breads bekow 970g') plt.show()
And the result would look something like this
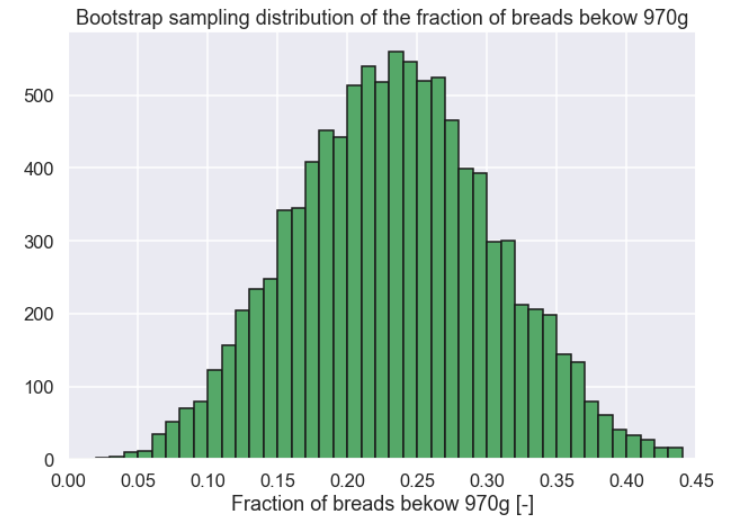
Finally, calculate the confidence interval
CI_low = np.percentile(Bootstrap_below,5) CI_high = np.percentile(Bootstrap_below,95) print('Confidence interval low = ' + str(np.round(CI_low,2))) print('Confidence interval high = ' + str(np.round(CI_high,2)))

OK! We have calculated the confidence interval of the proportion of breads with a weight below 970g! That would be more or less impossible using analytical methods but with the bootstrap technique it is the same no matter what the statistic you are interested in! One thing that can be said about the results here. The confidence interval is pretty wide so there is a lot of uncertainty about the fraction of breads with a weight below 970 g. To increase the accuracy of the estimate you want to increase the sample size which you probably should do in a situation like this. You show the results to your boss and he is really impressed.

Perhaps we should end with some work of caution regarding the bootstrap technique. It is assumed that the sample you have, in our case 25 weight of breads, is representative of the whole population. This mean, for instance, that there need to be a sufficient number of data points in your sample (you can imagine if you just have measured 2 breads it will not work). Moreover, Not all test statistics can be investigated in a good way. For instance the sampling distribution of the maximum or minimum value within a sample is not suitable to estimate by a bootstrap technique
Time to conclude
So that's it for now! In this first blog post on statistical inference we have talked about that we can us a summary statistic to report a property of a bunch of values. We also discussed that we can estimate a summary statistic for a population by applying the same summary statistic to a sample taken from that population. Finally we used a bootstrap technique to calculate how certain we are about our estimation, this was reported by a confidence interval.
The next blog post on the topic of statistical inference will cover how to do hypothesis testing using computational techniques so stay tuned!
As always, feel free to contact us at info@gemello.se