This is the second part in the statistical inference series and in this blog post we are going to take a look at hypothesis testing. This is something that almost everyone that has had some training in statistics has encountered. When I had training in statistics and did some exercises on hypothesis testing it usually always turned into a discussion of which test you should use to get the right answer (as I remember there were quite a few to choose from). Then you got a p-value from the test (you never really understood what that number was) and then you tried to make some rule just to remember what consequence a low p-value might have, like:
If p is low, H0 got to go...
I don't like this approach that much as it is (at least for me) almost impossible to remember what these different tests actually mean and what kind of assumptions go into them. Sure you will get some numbers out of the test, but to me it was never that clear what it actually meant. So, the idea for this blog post is to take a computational approach which can be made in a much more unified way and, hopefully, in a much more understandable way to. So let's get to it!
This is how we do it
The question that you would like to answer with a hypothesis test can be formulated as:
What is the probability of getting a result at least as extreme as the one you got just by chance?
and, to perform a hypothesis test you should (always) do the following steps:
- Choose a test statistic that you like to investigate and calculate it for the data from the test
- Formulate a Null hypothesis, H0, and an alternative hypothesis, H1
- Make a simulation under the null hypothesis to generate data
- Apply the same test statistics to the simulated data
- Calculate the fraction of the simulate test statistics that are at least as extreme as the test statistic of the data of the test (the p-value)
- Make a judgment if so unlikely to see the result from the test under the null hypothesis that you reject it in favour of the alternative hypothesis.
And we are done! That's all folks! Well this piece of advice is very similar to:

and I tend to agree on that. But why don't we take a look at one or two examples to (hopefully) make it clearer!
Back at the bakery
Once again we are back at the bakery. This time you, as the quality assurance manager, are faced with a problem related to cookies, more precise cookies in the shape of rabbits.

The problem is the ears of the rabbits, they sometimes fall off when the cookies are stored. To solve this problem there have been some modifications done to the recipe of the paste and a test has been conducted where the number of "defect" (meaning no ears) cookies was measured. A sample of the size 40 cookies was taken from the old and new recipe and the number of defects (meaning no ears) cookies were 16 and 6, respectively. So the new recipe seems to perform (much) better but let's follow the steps above to investigate the situation in more detail.
Choosing a test statistic
Starting off with choosing a test statistic and calculating it for the test data. In this case it seems reasonable to look at the proportion of defect cookies and calculate the difference between the old and the new recipe. Let's start up a jupyter notebook and get started.
import numpy as np import scipy as sp import matplotlib.pyplot as plt import seaborn as sns sns.set(context='talk') sample_size=40 defect_old = 16 defect_new = 6 print('Defect rate old recipe = ' +str(defect_old/sample_size)) print('Defect rate new recipe = ' +str(defect_new/sample_size))
The output gives that we have a reduction of defect cookies from 40% to 15% that is a difference of 25% units.
Formulate a Null hypothesis and an Alternative hypothesis
Now, the next step is perhaps a bit more tricky if you are not that familiar with formulating a null hypothesis, H0, and an alternative hypothesis H1. For some reason I always think of this scene from the movie Spaceballs by Mel Brooks when it comes to formulate the null hypothesis

I.e. whatever thing (improvement) you might think you have found, it is not real, this is the null hypothesis. We assume that the null hypothesis is true and as long as we don't have strong evidence that this is not the case. So, in our specific case where we are interested in investigating whether the new recipe is better than the old one we simply assume that this is not true i.e. the two recipes are equal when it comes to the fraction of defect cookies. The alternative hypothesis, H1, is that the new recipe actually is better than the old one.
Simulate the null hypothesis
So, now that we have decided on the null hypothesis and the alternative hypothesis we come to the next step, simulate data under the null hypothesis. This can also be a bit tricky and there are several ways to do this. The objective is to generate a lot of different samples of the same size as the ones we have (40 cookies with the old recipe and 40 cookies with the new recipe) under the assumption that the null hypothesis is true i.e. there is no difference between the different recipes. Let's try a simulation technique called shuffling! The idea behind this technique is that if the null hypothesis was true (now difference between the recipes) it would not mean anything if the cookie came from the old or the new recipe (since they would have the same performance). This can be done by throwing all the (80) cookies in the same bowl, mixing it around and then picking 40 cookies at random and say that they came from the old recipe and the remaining 40 cookies came from the new recipe. It took quite a few of words to explain this but it is really easy to write the code for this using the numpy function choice.
# put all cookies in the same array defect_vector = np.zeros(80) defect_vector[0:22] = 1 shuffle = np.random.choice(defect_vector,size=len(defect_vector),replace=False) g1 = np.sum(shuffle[0:sample_size]) / sample_size g2 = np.sum(shuffle[sample_size:]) / sample_size d = g1 - g2
Now, we do the shuffling a lot of times and for each time calculate the difference of the proportion of defect cookies for the new and the old recipe.
diff = [] for _ in range(0,100000): shuffle = np.random.choice(defect_vector,size=len(defect_vector),replace=False) g1 = np.sum(shuffle[0:sample_size]) / sample_size g2 = np.sum(shuffle[sample_size:]) / sample_size diff.append(g1-g2) diff = np.array(diff)
And here is the plot of the result.
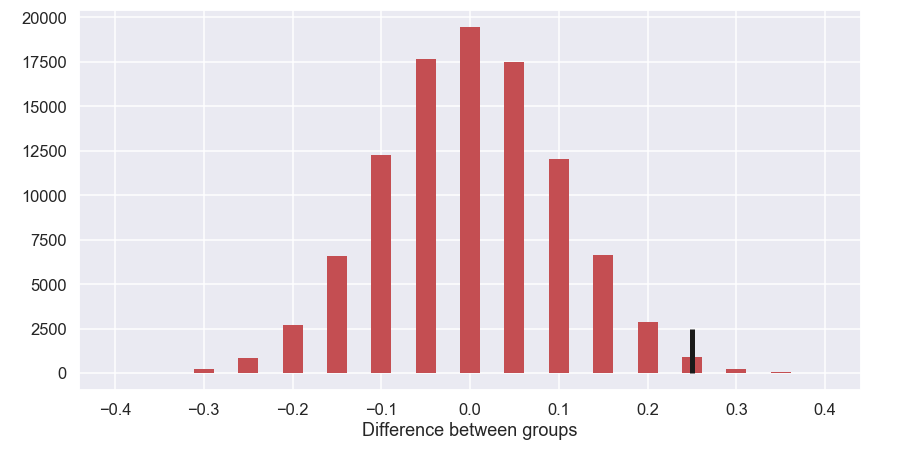
Now, let's have a look at this plot and see if we can make some sense out of it. The most common value is zero which seems reasonable since the simulation assumes that the two recipes are identical. A difference larger than +-40% seems almost impossible but how does the actual difference of 25% units fit into this result?
Compare simulated data to "real data"
The actual difference of 25% is indicated by the black vertical line. If we calculate the fraction of the simulated results that gave a reduction of at least 25% it will answer the original question of how likely it would be to get a result at least as extreme as the one we got just by chance. Let's do that!np.mean(diff>=0.25)
which gives an output of 0.01171. So if the null hypothesis was true, the probability of getting a result at least as extreme as the one we got is just above 1%... this is sort of unlikely. Now we have to decide if we think that just above 1% probability is so unlikely that we do not think that this could have happened by chance. For some reason it has, in many fields, been assumed that a probability below 5% is said to be so unlikely to happen so we reject the null hypothesis in favour for the alternative hypothesis and the result is said to be statistically significant.
Sweet! we are now done with all the steps in the hypothesis testing and we found out that the result is statistically significant (at a level of 5%). So just to repeat once more, what does this actually mean? It means that the new recipe most likely is better than the old one
Well, this is encouraging. You remember that a very long time ago there was formulated a "defect ears for cookies that look like rabbits"-specification that we never have been able to fulfill. You start to think that this can be the moment when it happens. The specification states that the long term proportion of "defect ears for cookies that look like rabbits" should be below 20%. In the test that we did for the new recipe we only had 15% cookies with defect ears... Alright we have now fulfilled the specification!! Or... wait a minute... could we have got this result just by chance... Let's do another hypothesis test.
Here we simply follow the same steps as above, starting off with the test statistic. This is the same as previous, we are interested in the proportion of defective cookies. Next, we should formulate the null hypothesis and the alternative hypothesis. In this case we hope that the new recipe will generate a proportion of defective cookies that is below the specification limit of 20% (long term), so for the null hypothesis we state that this is not true (remember the Spaceballs scene). Now, let's make a simulation under the null hypothesis and investigate what the data would look like if the null hypothesis was true. This is done in just one line of code
H0_samples = np.random.binomial(n=40,p=0.2,size=1000000) / sample_size
the histogram
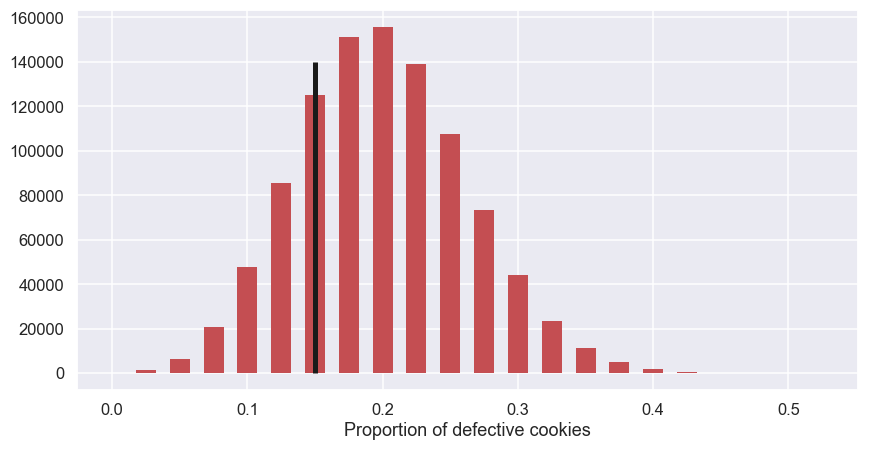
And, finally, for the simulated data you calculate the fraction (probability) that has has a test statistic at least as extreme as the "real" test data
print('p-value = ' + str(np.mean(H0_samples<=0.15)))

Hmm... the p-value is almost 30%... this means that there is a probability of approximately 30% to see this result even though the specification is not fulfilled... This is not strong evidence that we have fulfilled the specification
Time to conclude
To finish off this blog post, I would just like to take a look at some aspects of the p-value.
So, does a p-value below the in advanced set threshold automatically mean that the improvement is real?
Well actually no... Even though not mentioned explicite above, the effects that we are investigating with a hypothesis test are variation due to sampling. We have not considered any other thing that might influence the data such as not independent data, measurement errors and so on. So if you have obtained a positive test from a hypothesis test you can tick off the possibility that the result occurred due to sampling and start worrying about other things that might have gone wrong
What is the accuracy of a p-value?
For some reason this threshold for the p-value (almost always 5%) can be taken very seriously. It should be clear from the computations above that there are some modelling decisions that have to be made in order to calculate a p-value. These modelling decisions will (for sure) affect the p-value. So if you think that a p-value of 4.8% is WAY better than 5.2% I think that you have way too much trust in the accuracy of a p-value
If I have got a low p-value (say below 5%) does this mean that the results are important?
Once again, not necessarily. It could be that the improvement we have is too small to be considered interesting even though it is statistically significant. Here I would also like to say something on how to present results. The by far worst way of presenting the result we got when we compared the old and new recipe is to say that the new recipe is better and the p-value is 0.01171. What is really bad about this is that the actual effect, going from 40% to 15% is not mentioned. The size of the effect (improvement) is the most important thing to report! Then you could report something about how certain you are about the improvement (like a confidence interval) and, last and least, you can add if the result is statistically significant meaning that the two groups probably not are equal.
Ok, that was it for this time! Not that much code in this blog post but hopefully the concept of hypothesis testing was explained in a good way.
As always, feel free to contact us at info@gemello.se