This is the third and last part of the "Statistical Inference"-serie and in this blog post we are going to take a look at (a simple form of) regression analysis. Like we usually do, the theoretical findings are applied to a, sort of, real world problem and in this blog post we are investigating the fuel consumption of cars. The data set only contains information about pretty old car models (from 1970 to 1982) so the situation is a bit different from the modern cars of today (so no Teslas in the data set)
So fasten your seatbelt and let's go!

Show me the data
The first thing we should do is to load the data set and have a look at it, here we are using Pandas to handle the import. When I downloaded the data it was stored in two different csv-files so both files have to be imported
import numpy as np import scipy as sp import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set(context='talk') df_load_1 = pd.read_csv('cars1.csv',na_values='?') df_load_2 = pd.read_csv('cars2.csv',na_values='?')
To smash these two dataframes into one we can use the pandas command concatenate.
df_load = pd.concat([df_load_1,df_load_2]) df_load.head()

Ok, let's have a look at the content of the files we just imported. The first column just represents an index. The second column represents the thing that we are interested in, mpg or miles per gallon. In the next 5 columns, some other stuff related to the cars are listed. The first thing we will do is to just recalculate some of the variables to units that I'm more familiar with. I would, for instance, like to have the weight in kg and not lbs and, moreover, the fuel consumption should be given in liter/100km and not miles per gallon (mpg). Let's create a new dataframe containing the infor that we are going to use for the analysis.
df = pd.DataFrame() df["cylinders"] = pd.to_numeric(df_load["cylinders"], downcast="float") df["displacement"] = pd.to_numeric(df_load["displacement"], downcast="float") df["horsepower"] = pd.to_numeric(df_load["horsepower"], downcast="float") df["weight"] = pd.to_numeric(df_load["weight"], downcast="float") / 2.2046 df["acceleration"] = pd.to_numeric(df_load["acceleration"], downcast="float") df["model"] = pd.to_numeric(df_load["model"], downcast="float") df["fuel_consumption"] = 235.214583 / pd.to_numeric(df_load["mpg"], downcast="float") df = df.dropna() df.head()
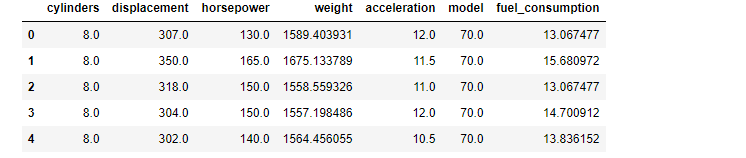
And now, as the heading suggests, let's plot the data!
plt.figure(figsize=(7,7)) sns.scatterplot(x='weight',y='fuel_consumption',color='r',s=40,data=df,edgecolor='none') plt.xticks(rotation=90) plt.figure(figsize=(7,7)) sns.scatterplot(x='horsepower',y='fuel_consumption',color='r',s=40,data=df,edgecolor='none') plt.xticks(rotation=90) plt.figure(figsize=(7,7)) sns.scatterplot(x='model',y='fuel_consumption',color='r',s=40,data=df,edgecolor='none') plt.xticks(rotation=90) plt.show()
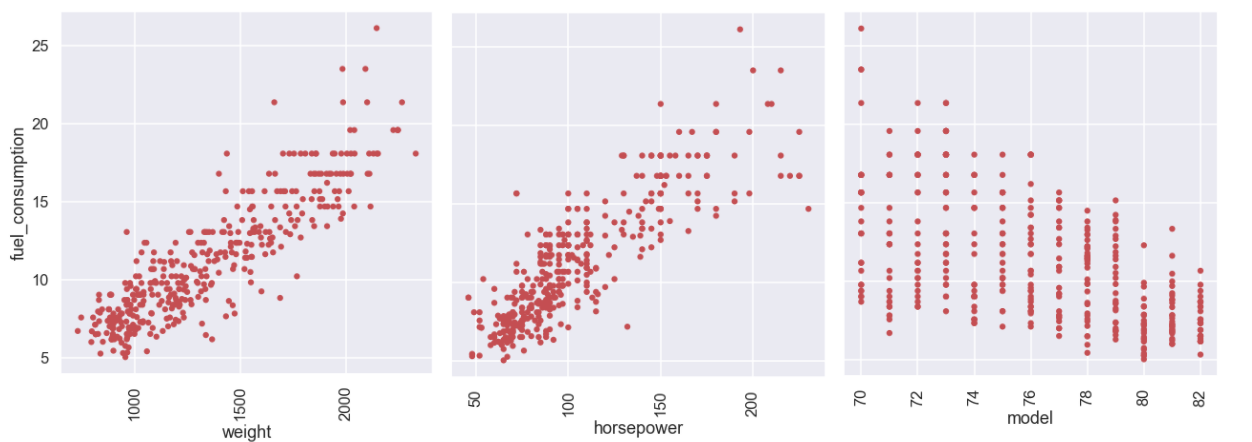
On the vertical axis we have the fuel consumption in liter/100km and we have weight, horsepower and model year on the different x-axis. Cool! Remember, we would like to describe the y-variable, in this case the fuel consumption, as a function of the different x-variables and just from the pictures above there seems to be something going on... interesting!
Bring me a model
Ok, we are looking for a relationship between the fuel consumption and some variables. In a general way this can be written as:
\[ {\bf y} = {\bf f}({\bf X}) \]
So... what about the function \({\bf f}({\bf X}) \) ? A simple but yet very versatile and powerful model is the linear regression model that can be written as:
\[ {\bf y} = \beta_0 + \beta_1\cdot {\bf x}_1 + \beta_2\cdot {\bf x}_2 + ... + \beta_n\cdot {\bf x}_n + {\epsilon} \]
Or, if you are a bit fancy, in matrix notation
\[ {\bf y} = {\bf X} \cdot {\bf \beta} + {\bf \epsilon} \]
(we will use the matrix notation further down the road so it is actually a good idea to get use to it already now)
What is meant by the word linear is that the terms are added together. As you might have guessed, the \(\bf y \) in this case is the fuel consumption and the \({\bf x}_i \) are the different variables (like weight of the car, the horsepower and so on). The term \(\bf \epsilon \) is the error (or residual) which might be due to random factors like measurement error, or non-random factors that are unknown
Nice! Now we have a model (or at least an idea of what the model will look like), what about the model parameters \({\bf \beta}_i \) ? Well, different values of the parameters will make the model behave in different ways so how do we choose the parameters to give us the "best" model? Of course we have to be a bit more precise about what we mean by "best" and there are several options that make sense. We are going to use the approach that is the most common one and try to choose the model parameters so the response (the \(\bf y \)-variable) is as close as possible to the data. Let's try it out!
Minimize the errors
Now, Let's have a look at a sort of general picture of some data and a model
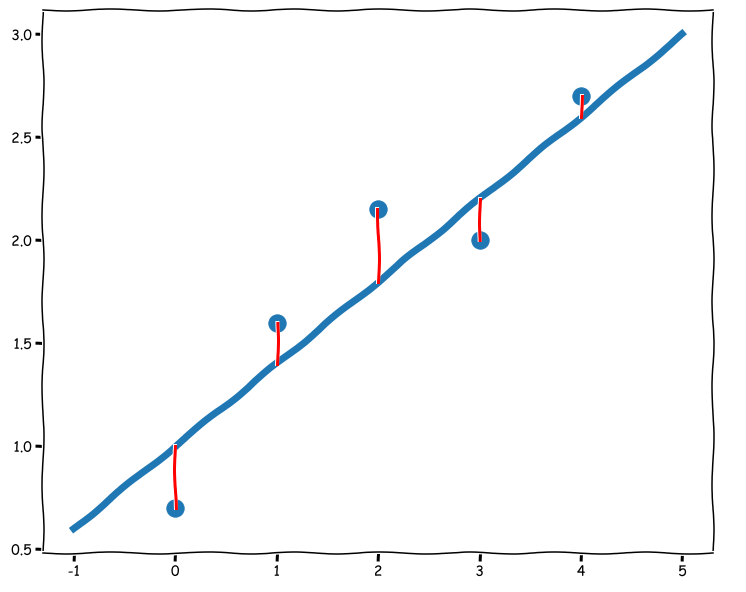
The blue dots represent the actual data, the blue line represents the model and the red lines are the (vertical) difference between the data and the model, the error. So, how can we use this to choose the "best" parameters for the model? One suggestion is to make a sum of all the squared errors i.e. look at each error, calculate the square of it and add them together (giving a scalar number). The best model parameters are then obtained when we find the smallest value of the sum of squared errors. This is sometimes referred to as Ordinary Least Square (OLS) and there are some reasons why this is a nice way to go, such as:
- Since the errors are squared we treat both negative and positive errors (model value lower or higher that data) the same way
- Squaring the values gives larger errors more impact on the total sum (but not too much)
- It can be handled in a mathematical effective way
So, as we are interested in the model parameters that give the smallest sum of squared error this turns into a minimization problem. There are several ways to deal with these problems but since we are using this linear regression model there is actually a really fancy analytical solution! The solution requires some linear algebra so if you are not into this kind of stuff feel free to skip it. So, remember that the model we are using can be written as:
\[ {\bf y} = {\bf X} \cdot {\bf \beta} + {\bf \epsilon} \]
Now. Let's make the interpretation that these three quantities are vectors in a higher dimensional space. We can make a drawing of this (here only use 3 dimensions in order for me to draw the picture...)
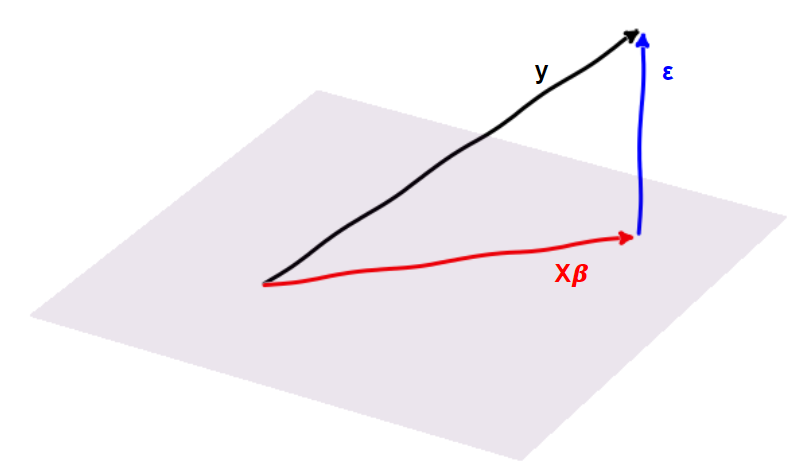
The columns of \({\bf X}\) can be seen as vectors all lying in a plane. We would like the error, i.e. the difference between \({\bf y}\) and \({\bf X} \cdot {\beta}\), to be zero but we can't get there since we are stuck in the plane defined by \({\bf X}\). So what is the best we can do? Well, the closest we can get is when the error vector \({\bf \epsilon}\) is perpendicular (or orthogonal) to the plane defined by \({\bf X}\). If this should be true, the scalar product between every column of \({\bf X}\) and \({\bf \epsilon}\) is zero. Let's write that down.
\[ {\bf X}^T \cdot {\bf \epsilon} = {\bf X}^T \cdot ({\bf y} - {\bf X} \cdot {\bf \beta} ) = {\bf 0} \]
and after rearrangement
\[ {\bf X}^T \cdot {\bf X} \cdot {\bf \beta} = {\bf X}^T \cdot {\bf y} \]
Super! Now we can just multiply by the invert the quantity \({\bf X}^T \cdot {\bf X} \) to get a closed form of \({\beta} \)
\[ {\bf \beta} = ({\bf X}^T \cdot {\bf X})^{-1} \cdot {\bf X}^T \cdot {\bf y} \]
And there you have it! So, if you have \({\bf y}\) and \({\bf X}\) you can find the \({\bf \beta}\) values giving the best fit (minimizing the squared errors) using the formula above
Now, we have a general view on what the model should look like and we have derived a way to fit the model to data. Awesome! It is about time that we use this knowledge.
Let's try it out!
So let's start with something rather simple. Let's assume that the fuel consumption is a function of the weight of the car. So recall the plot from above
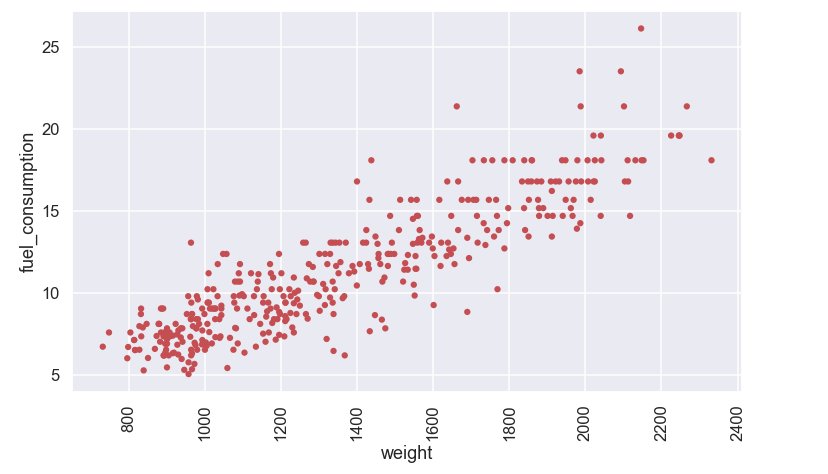
Let's fit the model to the data using the formula above. This means that it is finally time to return to the jupyter notebook and do some more coding!
# data X = np.zeros((len(df),2)) X[:,0] = 1 X[:,1] = df['weight'].values y = df['fuel_consumption'].values # fit model AA = np.matmul(X.T,X) BB = np.matmul(X.T,y) Beta = np.matmul(np.linalg.inv(AA),BB) y_hat = np.matmul(X,Beta) print(Beta) # error epsilon = y_hat - y # plot data and model plt.figure(figsize=(12,7)) sns.scatterplot(x='weight',y='fuel_consumption',color='r',s=40,data=df,edgecolor='none') x_plot = np.arange(700,2400) plt.plot(x_plot, Beta[0] + Beta[1]*x_plot,'r',lw=5,alpha=1.0) plt.xticks(rotation=90) plt.show()
The values of the two model parameters are \(\beta_0\)= -0.8944 and \(\beta_1\) = 0.008991. Moreover, the plot looks like this
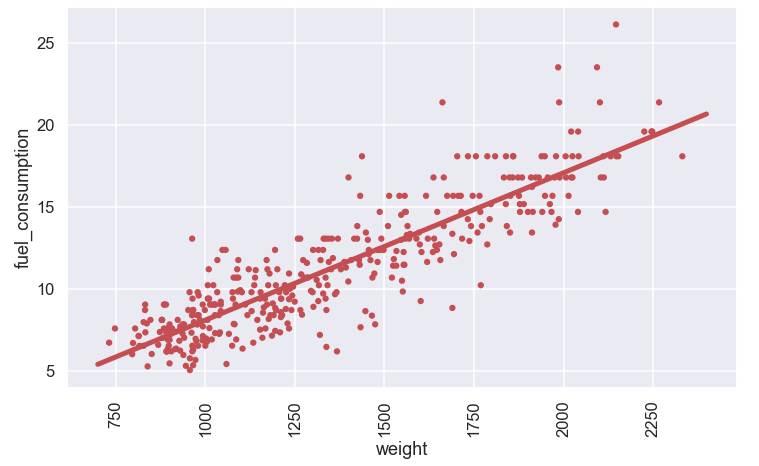
Just a few words on the interpretation of the \(\beta_i\) values. The first term \(\beta_0\) is the intercept of line i.e. the value of the fuel consumption for a car with a weight of 0 kg (hmmm..). The second term, \(\beta_1\), is the slope of the line giving that for every kg that the weight of the car increases the fuel consumption will increase with 0.008991 liter/100km. Nice! The line seems to fit the data rather well. Sure there are some values that are quite far off... So, how good of a job does a simple model like this one represent the data? Usually a quantity called coefficient of determination or \(R^2\) (r squared) is used in a situation like this. The coefficient of determination is defined as
\[ R^2 = 1 - \frac{SS_{res}}{SS_{total}} \]
where
\[ SS_{res} = \sum_{i}^m \epsilon_i^2 \], \[ SS_{total} = \sum_{i}^m (y_i - \bar{y})^2 \]
Here the term \(\bar{y}\) is the mean value of all data points for the fuel consumption.
So if the model matches all data points i.e. the error is zero at all data points the \(R^2\) value is 1. If we would fit a constant model with \(\beta_0\) taking on the mean value of all the data points the \(R^2\) value would be 0. Models that are worse than that would have negative \(R^2\) value. One can say that an \(R^2\) value give a measure of how much of the total variation that is captured by the model. Let's write a function that calculates the \(R^2\) value.
def R_squared_calc(y,epsilon): SS_epsilon = np.sum( (epsilon)**2 ) SS_total = np.sum( (y-np.mean(y))**2 ) return 1 - SS_epsilon/SS_total R_squared_calc(y,epsilon)
And, with this at hand we calculate the \(R^2\) value for the model above to 0.783
OK, so far there has not been so much statistical inference in this blog post so let's get into that! As always when it comes to statistical inference, you should ask yourself:
What if we did the test again?
In the first blog post on statistical inference we used the bootstrap method to construct confidence intervals for different test statistics and we will use a similar approach here as well. Similar to what we did in the blog post on confidence intervals we are going to assume that the model we just got is "true", I mean, we do not have any other information so this is our best guess. Then we are going to take bootstrap samples from the error vector and add these to the original model. Here it is assumed that the magnitude of the errors is not dependent on the value of the input variables, this is called Homoscedasticity. Now we have a "new" data set which we will fit the model to, giving a new set of \(\beta_i\) values. This procedure is then repeated for a large number of times and for each time the resulting \(\beta_i\) values are stored. Let's write that in code
AA = np.matmul(X.T,X) n_bootstrap = 10000 Beta_vector = np.zeros((n_bootstrap,len(Beta))) for ii in range(0,n_bootstrap): boot_y = y_hat + np.random.choice(epsilon,size=len(epsilon),replace=True) BB = np.matmul(X.T,boot_y) boot_beta = np.matmul(np.linalg.inv(AA),BB) Beta_vector[ii,:] = boot_beta
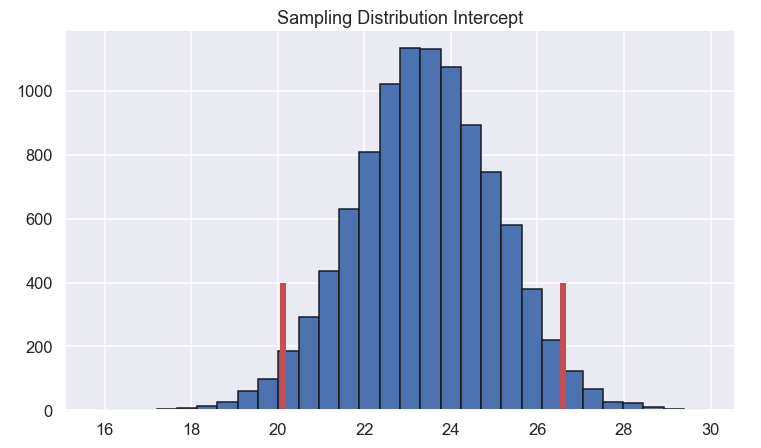
Now we plot the histogram of \(\beta_0\) and \(\beta_1\) so we can get a feel for how large variation they have
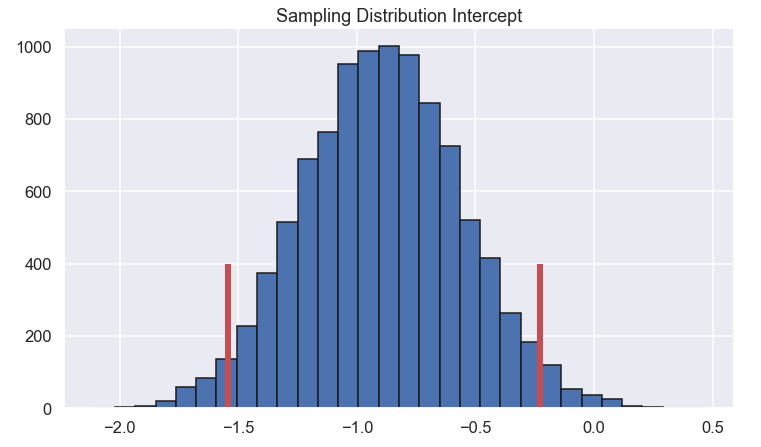
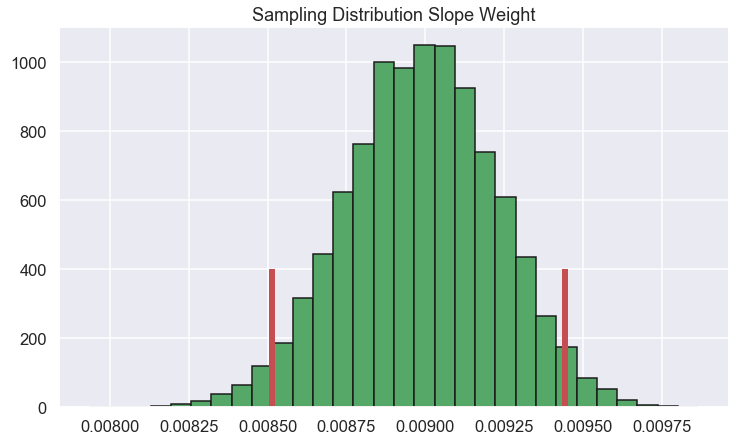
Here the 95% confidence interval for the two parameters are marked with vertical lines.
Alright, well done! We can conclude that we are pretty confident that the slope is somewhere in the range of 0.00851 and 0.00944.
So, what if we would like to improve the model... One idea would be to include additional terms so why don't we add borth quadratic terms of the weight as well as the term weight to the power of three
# data X = np.zeros((len(df),4)) X[:,0] = 1 X[:,1] = df['weight'].values X[:,2] = df['weight'].values * df['weight'].values X[:,3] = df['weight'].values* df['weight'].values* df['weight'].values y = df['fuel_consumption'].values # fit model AA = np.matmul(X.T,X) BB = np.matmul(X.T,y) Beta = np.matmul(np.linalg.inv(AA),BB) y_hat = np.matmul(X,Beta) epsilon = y_hat - y # plot plt.figure(figsize=(12,7)) sns.scatterplot(x='weight',y='fuel_consumption',color='r',s=40,data=df,edgecolor='none') x_plot = np.arange(700,2400) plt.plot(x_plot, Beta[0] + Beta[1]*x_plot + Beta[2]*x_plot*x_plot + Beta[3]*x_plot*x_plot*x_plot ,'r',lw=5,alpha=1.0) plt.xticks(rotation=90) plt.show()
Here is the model fitted to the data
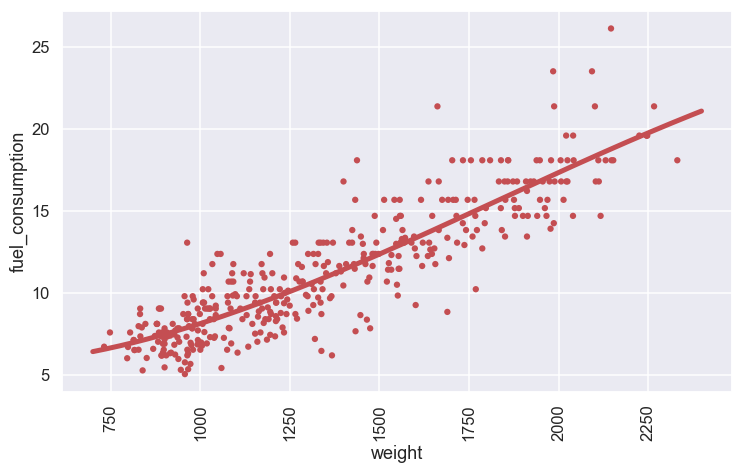
Well, it does not look that bad... But what if we look at the confidence intervals of the different \(\beta \) parameters? (Here we will just look at the slope term \(\beta_1\))
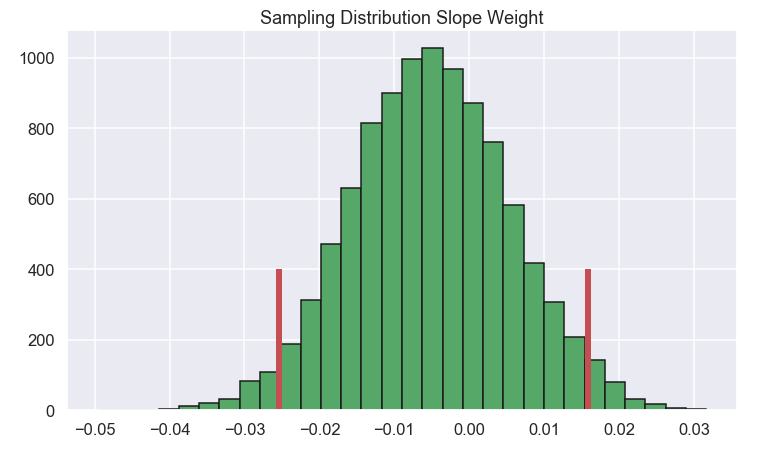
Ok this looks a bit different... Let's have a closer look at the parameter related to the weight. Here we can see that the confidence interval ranges from -0.025 to 0.016 so for some cases the parameter is positive and for some it is negative. This means that we can not say with any great confidence that this parameter is different from zero. The story is similar from the other parameters as well. This is a good indicator that the model we have chosen perhaps is a bit too complicated so the original model with just a linear term of the weight is probably a better choice.
One more try
Well, adding more terms related to the weight did not turn out that successful. Let's give it one more try with adding terms but in this case let's add some more linear terms: horsepower and model. It is going to be difficult to plot the model since we need more dimensions to visualize it. So let's fit the model to the data, calculate the \(R^2\) value and plot the distribution of the model parameters as well as calculate their confidence intervals.
First the code to fit the model
# data X = np.zeros((len(df),4)) X[:,0] = 1 X[:,1] = df['horsepower'].values X[:,2] = df['weight'].values X[:,3] = df['model'].values y = df['fuel_consumption'].values # fit model AA = np.matmul(X.T,X) BB = np.matmul(X.T,y) Beta = np.matmul(np.linalg.inv(AA),BB) y_hat = np.matmul(X,Beta) epsilon = y_hat - y
And then we calculate the \(R^2\) value for this model
R_squared_calc(y,epsilon)
giving a value of \(R^2\) = 0.881. So if we compare it to the \(R^2\) for the model with just the weight as input parameter we see an improvement.
Then the code for the bootstrap part
Boostrap_samples = 100000 Beta_vec_3 = np.zeros((Boostrap_samples,len(Beta))) for ii in range(0,Boostrap_samples): AA = np.matmul(X.T,X) BB = np.matmul(X.T,y_hat + np.random.choice(epsilon,size=len(epsilon),replace=True)) Beta = np.matmul(np.linalg.inv(AA),BB) Beta_vec_3[ii,:] = Beta
And finally, we plot the distribution of the different \(\beta_i \) parameters.
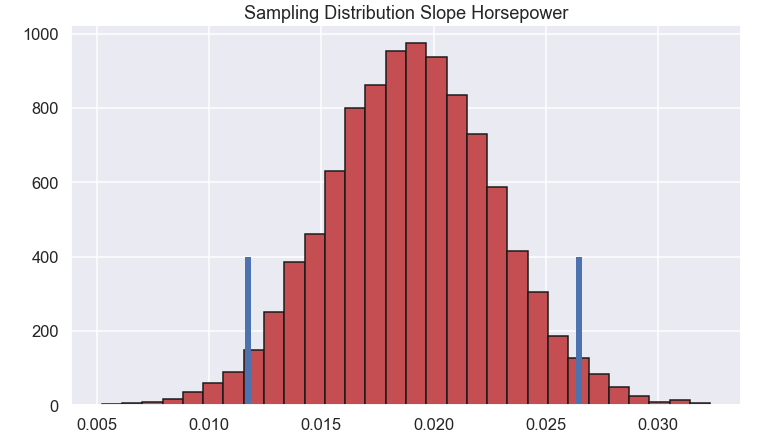
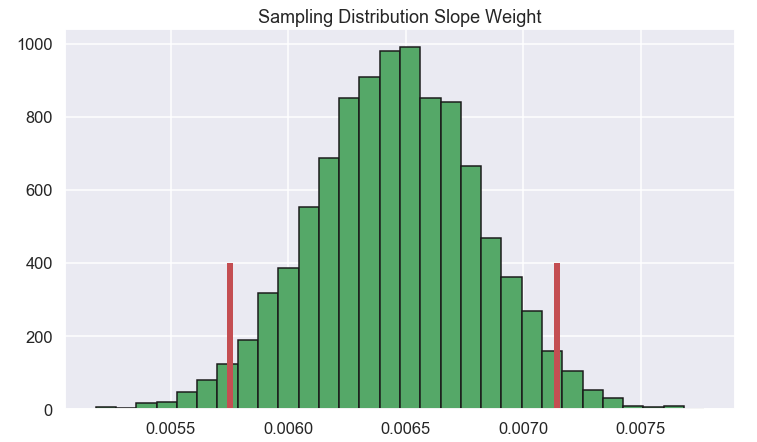
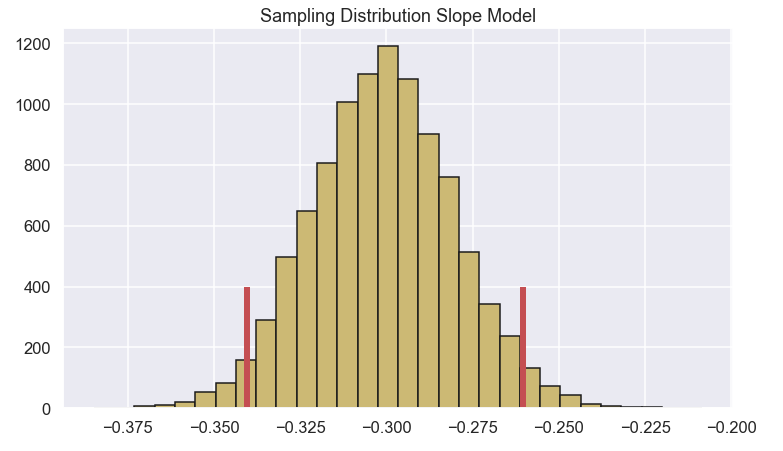
Ok Nice. We can see that none of the confidence interval of the different parameters contain 0, excelent!
Time to conclude
So, this was the final blog post in the statistical inference series. We have learned that simulation methods like the bootstrap method and the permutation test can be used to calculate confidence intervals and to perform hypothesis testing. We have also seen that these computational methods are fairly easy to understand and intuitive to apply.
As always, feel free to contact us at info@gemello.se if you have any questions or suggestions of topics for a new blog post.