This is the first blog post on bayesian statistic.
The purpose of this blog post is to provide some short and (hopefully) understandable introduction to what bayesian statistics is all about. There are many books on Bayesian statistics but most of them will very quickly go into advanced mathematics which can be sort of frightening for people without the required knowledge. So the idea of this introduction of bayesian statistics is to show a minimum of equations and maths. Moreover, if you google bayesian statistics chances are pretty high that you will find stuff where you discuss philosophy and things related to this epic battle between people of Bayesian or Frequentist way to look at statistics. This will not be covered by this and the coming blog posts on Bayesian statistics.
So, let’s get started!
First of all some general words about statistics. One of the ideas of statistics is to be able to say something about a large population by just evaluating a smaller sample from this population. Often in engineering applications, the word population could be a bit difficult to understand. For instance, if we have a machine that produces units with a certain weight, the population could be “all” the units that will be produced in a near future. So you can think about this population also as a process that generates “data” and from this “data” we would like to say something about the process. Now, let’s dig into some Bayesian stuff.
The model
The first thing you need to consider when doing Bayesian analysis is to create a model of the process that could have generated the data. Let’s not go too deep into what a model is, more than it is a mathematical description that should capture the (by us considered) most important features of the process. The model usually has some parameters (dependent on the model) and, finally, if the model is given a set of parameters it can generate some data. A sketch with the purpose of summarising this description is given below
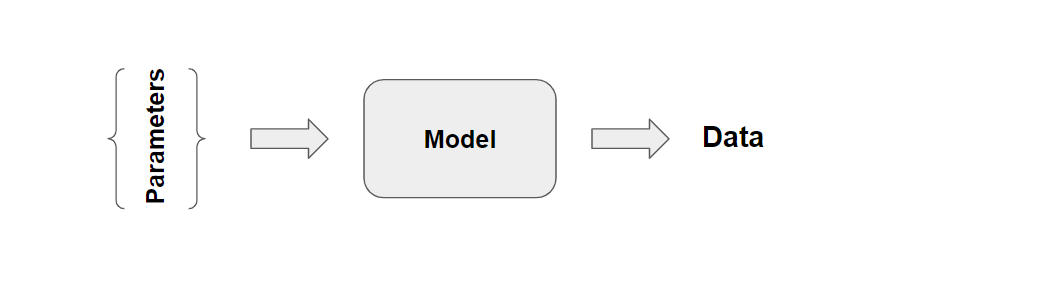
Now, just to make things easier, let’s look at a sort of simple model that only has two parameters, a binomial model. The binomial model will return the number of successes out of \(n \) independent experiments when the probability of a success is \(p \). This model would, for instance, be appropriate for modelling the outcomes from a number of coin flips (you would have to decide if heads or tails should be considered as success). We are actually that lucky that this model is directly available from numpy.random. If you flipped a fair coin (probability of heads \(= p = 0.5\) ) 20 times it would be written in code as:
np.random.binomial(n=20,p=0.5)
If you run this line a number of times you would get different outcomes since there is some randomness involved, in my case I got [16,7,11,...]. If you ran it many, many times (like 100 000 times) we would get sort of a distribution of the different outcomes
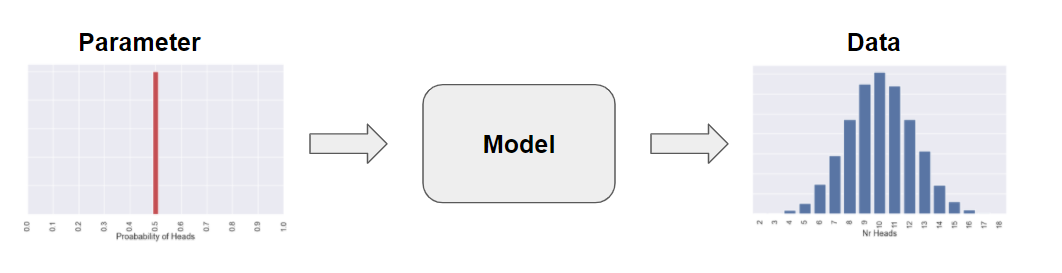
So for a certain (fixed) value of the parameter \(p\) (the graph to the left) we get a distribution of different outcomes for the data (the graph to the right). Moreover, we could calculate the probability to get a certain number of heads,say 8 out of 20, just by counting the number of times we get 8 heads and then divide it by the total number of trails (100 000). If you have looked at some of our previous blog posts we used this setup to calculate a p-value. We could get a bit more nerdy by saying that we could calculate the probability of the data given the parameter. We could even be that nerdy to introduce some mathematical notation like
\[ p(D|H) \]
This should be read as:
- the probability: \(p() \)
- of the data: \(D\)
- given: \(|\)
- the value of the parameter: \(H\)
So, if we have a fixed, known, value of the parameter we could run the model and get a distribution of different outcomes and from that calculate the probability of a certain outcome (data).
To be honest, so far we have not bumped into any Bayesian stuff… but that is about to change!
Looking at the coin flipping example above, a much more realistic scenario is that we flipped the coin 20 times and got (as an example) 8 heads. So let’s view the data i.e. the 8 heads out of 20 flipps, as fixed. Here, just to clarify, the data came from a random process (flipping a coin) but when you have the results it can be viewed as fixed. Then, by running the model “backwards” we would get a distribution for the parameter i.e. the parameter would be a random variable, c.f. the picture below.
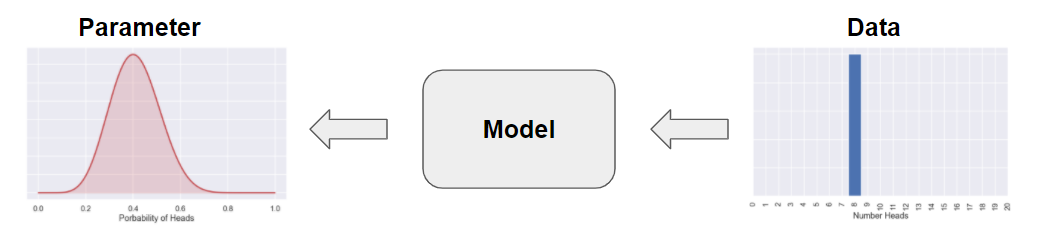
So, if we could find a way to get hold of the thing to the left, the distribution of the prameter \(p\), we would have found the probability of the parameter given the data, or
\[ p(H|D) \]
In a way, this is a much more natural quantity to be looking for since it is very similar to what we often ask for in “the real world”.
- We do some test (flip the coin)
- Get some results (data)
- From the data we would like to say something about the coin (the parameters)
Note here that the last step needs a model of the data generating process (flipping the coin). So, in a Bayesian setting we view the parameters of the model as a random variable and the data as fixed (this is actually a consequence of how to define probability)
ABC, It's easy as 1 2 3
Ok, now to the big question, how do I get from \(p(D|H) \), which could “easily” be obtained by running the model in “forward” direction, to \( p(H|D) \)???
Well, there are actually many different methods to do this but in this blog post we are going to use something called Approximate Bayes Computation (ABC). It is, as will be shown, a computational intensive (and inefficient) method but is (hopefully) easy to understand since all the mathematics is sort of hidden.
So, we have developed a model that we can run in the forward direction i.e. for a fixed number of probability for heads, \(p\), we can simulate the number of heads from \(n\) tests. Note that \(n\) is known since we can observe how many times the coin has been flipped. We have made an experiment where we flipped the coin 20 times and observed 8 heads (this is the data) and we are ultimately interested in the probability of the (value of the) parameters given this data. Now, let’s make an assumption…. why don't we assume that all values of the probability of getting heads, \(p\), are the same? This is in a way saying, I know nothing about this coin. Let’s generate a LOT of different values of \(p\) by using the numpy.random.uniform function
p = np.random.uniform(size=1000000)
Just to make sure that all values of \(p\) are equally likely we plot them in a histogram

This is often referred to as the prior distribution since it represents our beliefs about the parameter before we see the data.
Ok, that looks nice. Now, we use all these values of \(p\) and for each of them we run the model of the coin flipping process and obtain a number of heads
N = 20 heads = np.random.binomial(n=N,p=p)
Note that since the variable \(p\) is an array the output \(heads\) will also be an array of the same length as \(p\). Moreover, the number of heads found at a certain location in the array \(heads\) have been generated by the probability found at the corresponding location of the array \(p\). Let’s visualize the number of heads as a function of \(p\)
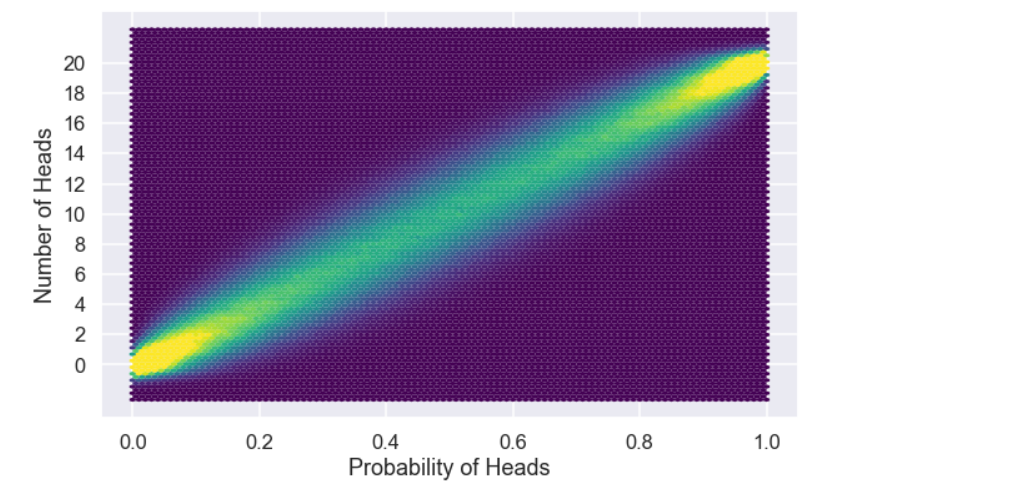
Here we have added some yitter to the values on the y-axis just to make the plot look nicer.
Now, get ready because here comes the final move…. We are looking for the quantity \(p(H|D) \) where we have a condition on the actual data (8 heads). To find this we look at all the occasions in the array \(heads\) when we got 8 heads and then find the corresponding probabilities.
p_given_data = p[heads==8]
And, finally a plot of the result
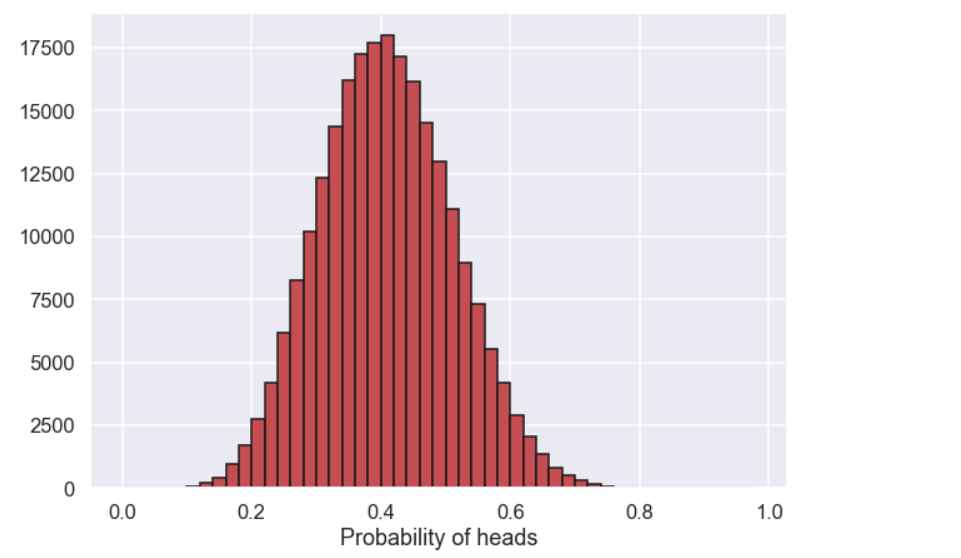
So, here we have a histogram of the probabilities that generated a result of 8 heads. What can we say about this? Well It seems like a value of 0.4 is the most probable and values above say 0.6 and below 0.2 are not that likely. A plot like the one above is often referred to as the posterior distribution since it in a way represents our beliefs about the parameter after we have seen the data. Moreover, what we could do is to report an interval where say 90% probability is contained.
np.percentile(p_given_data,[5,95])
This will give the result [0.25, 0.58]. This is called a credability interval and this means that there is a 90% probability that the value of the parameter is within this interval. Even though we are not going to talk about the difference between the bayesian and frequentist approaches we can note that there is a difference in interpretation between this interval above and what is called a confidence interval.
Well done! We have managed to perform all steps for estimating the probability of getting heads and the result was a distribution of different probabilities (I know it is a bit awkward to talk about probability of a probability but you should think about it as the probability of the values of the parameter \(p\) ). Now that we have done this "toy" example with flipping a coin let’s look at a more realistic example.
Back to the Bakery... Again
Let’s return to the same bakery as in this previous blog post, here we looked at cookies in the shape of rabbits. Some of these cookies were defective in the sense that their ears were broken. We are interested in estimating the proportion of cookies that are defective and for this we collected some data. A sample of 40 cookies were collected and among these 16 was defective. This is very similar to the coin flipping experiment above so let’s go through the different steps
- Create a model of the process
- Define a prior i.e. what do we think of the parameters before we see the data
- Calculate the posterior distribution, here we use Approximate Bayes Computation
For the model we can use the same as we did in the coin flipping example above. There are two possible outcomes for each cookie, ok or defective, which is analog to heads and tails for the coin. When it comes to the prior we can use the same approach as above since we do not have any other information at this moment. To calculate the posterior distribution we use the same steps as above for the Approximate Bayes Computation. Let’s write this in code (it will not be much)
# prior p = np.random.uniform(size=1000000) # ABC defective_cookies = np.random.binomial(n=40,p=p) posterior = p[defective_cookies == 16] # plot posterior plt.figure(figsize=(10,6)) plt.hist(posterior,bins=np.arange(0,1.0,0.02),color='r',edgecolor='k') plt.xlabel('Probability of Defective Cookies') plt.show()
And the posterior distribution looks like this
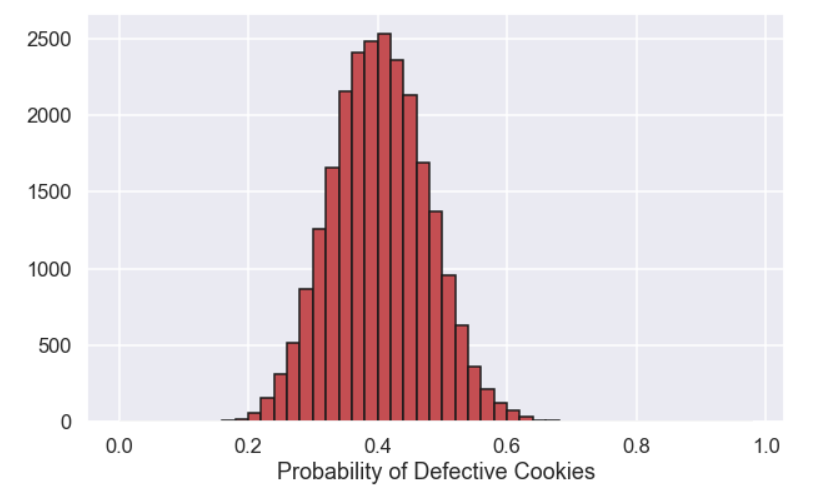
We can also calculate a 90% credibility interval as
np.percentile(posterior,[5,95])
giving the interval [0.28, 0.53]. So from the data we have, 16 defective cookies out of 40, we can say that there is a 90% probability that the proportion of defective cookies is between 28% and 53%.
What you see is (not always) what you get
Now, let’s take the opportunity to demonstrate how flexible this framework is. Suppose that the bakery has invested in a new vision system that automatically identifies cookies with defective ears (the system is of course powered by python). Testing of the vision system has shown that it does not have a 100% accuracy (at the moment). Instead there is a 20% probability that an ok cookie is reported as defective and a 20% probability that a defective cookie is reported as ok. Now we use the system to evaluate 40 cookies and it found 16 defective cookies. What can we say about the proportion of defective cookies given the information about the accuracy of the vision system?
For this we need a slight modification of the model. What is needed is an additional step where the vision system judges if the cookie is defective or not. Some of the cookies that actually are defective will be seen as ok and some of the ok ones will be judged as defective. Below there is some code with this additional step.
p = np.random.uniform(size=1000000) true_nr_defective_cookies = np.random.binomial(n=40,p=p) # additional step for vision system vision_nr_defective_cookies = [] for i in range(0,len(true_nr_defective_cookies)): current_nr_defective_cookies = true_nr_defective_cookies[i] def_to_ok = np.random.binomial(n=current_nr_defective_cookies,p=0.2) # defective cookies seen as OK ok_to_def = np.random.binomial(n=40-current_nr_defective_cookies,p=0.2) # OK cookies seen as defective detected_nr_defective_cookies = current_nr_defective_cookies - def_to_ok + ok_to_def # store vales vision_nr_defective_cookies.append(detected_nr_defective_cookies) # convert to numpy array vision_nr_defective_cookies = np.array(vision_nr_defective_cookies) # calculate posterior posterior_vision = p[vision_nr_defective_cookies == 16]
and the histogram of the posterior (together with the previous plot without the vision system )
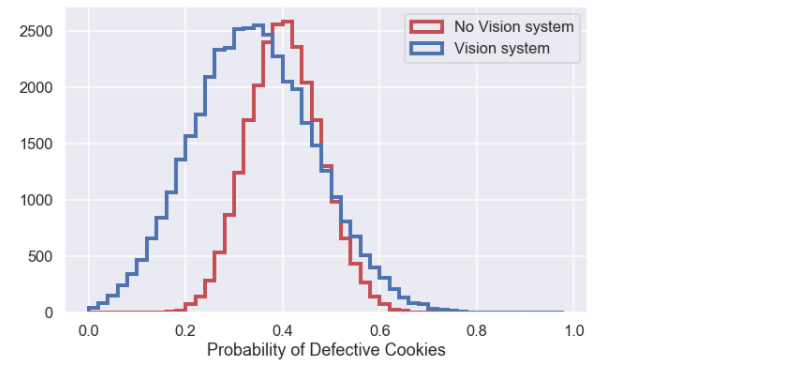
As can be seen from the histogram above the uncertainty in this case is larger than before (the same result but without the vision system) and a 90% credibility interval is bounded by [0.14,0.55]. The larger uncertainty comes from the somewhat mediocre performance of the vision system. The bakey probably needs to improve the performance of the vision system before taking it into use.
Well, I hope that this example demonstrates the flexibility of this approach. This additional step involving the vision system would be hard to incorporate using a sort of “out of the box” test. So when using a model based approach, as long as we can create a model of the data generating process we are in a good position of estimating the parameters.
Time to conclude
So, it is time to conclude this first blog post on Bayesian statistics. The intention was to show the basics of Bayesian statistics without any complicated mathematical expressions.
There are several more things to introduce within the framework of Bayesian statistics, for instance we have not mentioned Bayes' rule yet (have not fear it will come in the next blog post on this topic).
As you have probably noticed, the approach used here to calculate the posterior distribution (ABC) is (very) computational intensive. In the coming blog posts we will have a look at some different ways to compute the posterior which are less computationally demanding.
Well that was all for now! As always feel free to drop us an e-mail at info@gemello.se