So, this is the second part of the blog series: Introduction to Bayesian Statistics. In a previous post we had a look at what Bayesian statistics is about and we used a computational approach called Approximate Bayes Calculation (ABC) to calculate the things we were interested in.
In this blog post the idea is to dig a little further and introduce some new cool stuff, like Bayes' rule (it would probably be weird to have a short introduction to Bayesian statistics without Bayes' rule... ). Do not worry, it is not going to be math heavy (just some stuff in the beginning) instead we are going to introduce a new computational approach that is more efficient than the one used in the last blog post. So, just relax and let’s get to it!

Conditional probability
In this blog post we are looking at a sort of toy example to explain the basic stuff. In front of you, you have two bags that contain M&M’s of different colors. You know that one bag is from the year 1997 and the other bag is from the year 2008. The colors of the M&M’s for the two different years comes from the distributions below.
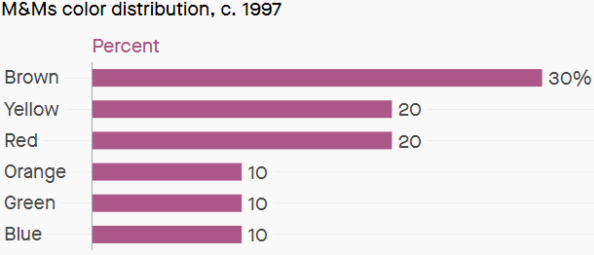
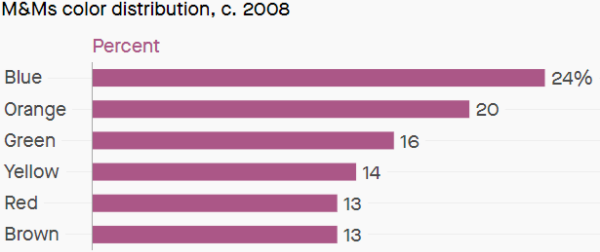
You choose one bag at random, take one M&M from the bag and it has a red color. what is the probability that the bag you have in front of you is from the year 1997 or 2008 (for the moment just forget that both 1997 and 2008 were a LONG time ago)?
So what would we like to know?
If we read the question formulated above one more time and then rephrase it in a more nerdy way one could say:
What is the probability that the bag is from 1997/2008 given that the color of the M&M is red?
or, by raising the geekeness level even further we could write it mathematically as
This is an example of conditional probability i.e. we would like to know the probability of something happening (the bag is from 1997) given that something else already has happened (we took a red M&M from the bag). The conditional probability is indicated by the pipe operator, |. in the expression above.
What do we know?
We know that the bag can either be from 1997 or 2008 (no other year is possible) and if the bag is from 1997 it is not from 2008 (seems ok...). To phrase this information in a nerdy way we could say that the different possibilities are Collectively Exhaustive and Mutually Exclusive.
We know the distribution of the different colors of M&Ms for the two different years (figures above) so if you know that the bag is from 1997 you know the probability of getting e.g. a red M&M. That is, you can calculate the probability
Or in words, what is the probability of a red M&M given that the bag is from 1997.
So, we know
Bayes' rule
Now, we take a step back and think about conditional probabilities. Let’s think of two different events called
Note that if these two event are independent of each other you could write
Now comes the “trick”: the probability of both
or, by just moving some terms around
and voila Bayes' rule

This expression forms the relationship between two conditional probabilities that we are looking for, Nice!
So, let’s change the
OK!, The thing on the left is actually what we are looking for... so do we know the stuff to let right?
Well
The term
Finally, the denominator,
Alright! Now we have all the parts to be able to calculate
So, what does this mean? Well, if we take one of the bags at random, open it and find a red M&M, we would think that there is a 61% chance that the bag is from 1997 (and 39% chance that the bag is from 2008)
Let’s just think about what has happened so far. We have used a fairly simple equation that relates conditional probabilities to each other in order to calculate the quantity we are interested in. This is not bad at all but in the next section we are going to take a look at a “different” interpretation of Bayes' rule that is really cool (at least the first time you see it).
Sign of the Time - The diachronic interpretation
First of all let’s just change the general events
Now, there is a special interpretation of Bayes' rule that is known as the diachronic interpretation. Diachronic means that something is happening over time, in this case how our belief about a hypothesis changes when we see some data.
The different terms has there own descriptive name
A somewhat loose description of Bayes' rule would be:
- I have some prior beliefs about a hypotheses: e.g. I am the best tennis player in the world
- I get some data: I lose 4 matches to my 10 years old daughter and three of her best friends
- I update my belief about the hypotheses: I am probably not the best tennis player in the world...
Bayes' rule is a mathematical tool that tells you how to update your beliefs about things.
Ok, let’s connect this to the M&M’s problem above. The hypothesis we have is that the bag is from 1997. The data is that we got a red M&M
Now, let’s start with the prior. What is our belief that the bag is from 1997 before we have seen what color we got? Well, we choose the bag at random so 1/2 is a reasonable value.
The likelihood in this case, expresses the probability of getting a red M&M given that bag is from 1997. This value is known to us since we know the color distribution of M&M’s from 1997.
Finally, the normalizing constant is a bit tricky to calculate and it represents the probability of getting a red M&M from any of the two bags. This was calculated above.
Well, now we have a different view of Bayes' rule using this interpretation. It turned out to be quite interesting. It more or less tells you how much you should change your belief about something when you see some new data, pretty cool I would say. Moreover, this is done in a very systematic way so it is rather easy to turn it into a computational framework.
Let’s get computational - A Bayesian update
It is now time to take Bayes' rule and turn it into a procedure for updating our beliefs when seeing some new data. Let’s construct a computational framework and apply it to the M&M problem, so fire up a Jupyter notebook and let’s get started!
First the “standard” imports
import numpy as np import matplotlib.pyplot as plt import seaborn as sns sns.set(context='talk')
Starting off with the hypothesis. In this case we have two different hypotheses: The chosen bag is from 1997 or 2008.
H = ['1997', '2008']
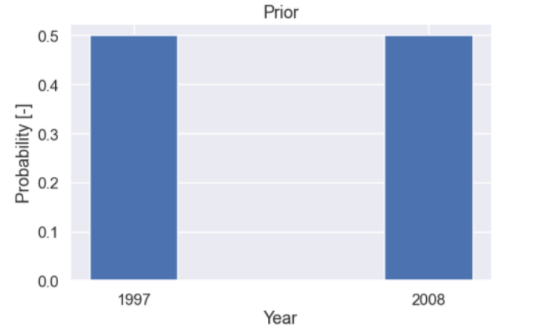
Nice, That was quite simple. Continue with the prior i.e. our belief about the probability that the bag is from 1997 or 2008 before we have seen any data. We know that the bag can not be from any other year than these two so the hypothesis we have stated covers all the possibilities (collectively exhaustive). This means that the sum of the probabilities from these two hypotheses must be one (100%). Moreover, it seems reasonable to assume that we do not have any higher probability to choose the bag from 1997 compared to 2008 so a prior with 50% probability for each hypothesis sounds ok
prior = np.array([1,1]) / 2
Let’s plot it as well
plt.figure(figsize=(8,5)) plt.bar(H,prior,width=0.3) plt.xlabel('Year') plt.ylabel('Probability [-]') plt.title('Prior') plt.show()
and the plot
This is running along very smoothly. Now comes a part that is a bit more tricky, the likelihood function.
From the definition above, the likelihood is the probability of the data given the hypothesis,
def likelihood(h,d): p = 0 dict_1997 = {"Blue":0.1,"Orange":0.1,"Green":0.1,"Yellow":0.2,"Red":0.2,"Brown":0.3} dict_2008 = {"Blue":0.24,"Orange":0.20,"Green":0.16,"Yellow":0.14,"Red":0.13,"Brown":0.13} if h == '1997': p = dict_1997[d] if h == '2008': p = dict_2008[d] return p
Nice! Just to be sure, let’s test the function
likelihood('1997','Red')
and the returned value is 0.2, seems OK!
Finally, let’s just create a list containing the observed data
D = ['Red']
I think that was it so far, now it is time to put it all together. Let’s write down the code and then go through the different steps
posterior = np.zeros(len(prior)) for i in range(0,len(D)): d = D[i] for j in range(0,len(H)): h = H[j] posterior[j] = prior[j] * likelihood(h,d) posterior = posterior / np.sum(posterior) prior = np.copy(posterior)
The different steps can be described as :
- Define a posterior as an array with the same size as the prior
- Loop over all data points (in this case it is only one)
- For each hypothesis calculate the numerator in Base rule i.e. prior * likelihood
- When this is done for all hypotheses, normalise the posterior so the sum is 1
Here is a plot of the posterior distribution
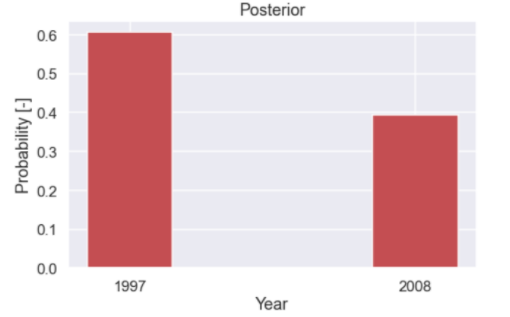
So, we started off with a prior (belief) that the probability of choosing a bag from 1997 was 50%, this since we just picked one bag at random. We opened the bag and took one red M&M (we got some new data) and then updated our beliefs about the probability that the bag is from 1997. After seeing the data we think that the probability that the bag is from 1997 is around 61%.
Here comes another cool thing! If we take one more M&M from the bag we can use our current posterior distribution as the prior for the new data, this is what the last line of code is doing in the code snipped above. Let’s try that out. We start all over but instead of taking one red M&M from the bag we now take a red, a green and a brown. Let’s write this in code and look at the posterior
D = ['Red','Green','Brown'] prior = np.array([1,1]) / 2 posterior = np.zeros(len(prior)) for i in range(0,len(D)): d = D[i] for j in range(0,len(H)): h = H[j] posterior[j] = prior[j] * likelihood(h,d) posterior = posterior / np.sum(posterior) prior = np.copy(posterior)
And the plot of the posterior distribution
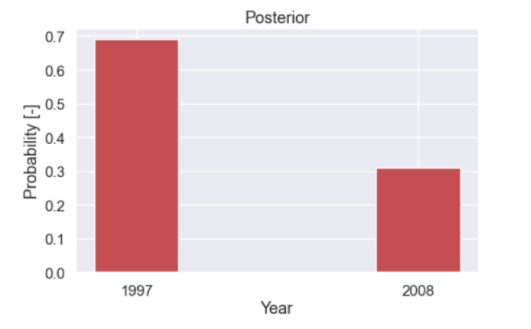
So after seeing these three different M&M we now think that there is a almost 70% probability that the bag is from 1997.
Time to conclude
In this blog post we have looked at a very central thing in Bayesian statistics, Bayes' rule. At a first glance it looked fairly trivial and the derivation of the rule was more or less straightforward. But after introducing the diachronic interpretation it turned into something awesome.
We also used Bayes' rule to construct a computational framework for doing a Bayesian update. It was not much code but it is very versatile and general.
In the next blog post on this topic we are going to look at a more realistic problem that seems more complicated at a start but this is where the computational approach comes in handy. So stay tuned.
That is all for now and, as always, feel free to contact us at info@gemello.se