Allright! New blog post on Bayesian analysis. In the previous post on this topic we used Bayes’ rule to calculate a posterior distribution of a parameter and now we have come to the big question:

In this blog post we are going to use the posterior distribution to make some inference. So fire up a jupyter notebook and let’s get started.
Is it better or not?
Okey, once again back at the bakery where we are looking at those cookies shaped like rabbis. The problem is that it is very difficult to get those ears to look good, they fall off the cookie or get deformed in some way. Not good.

Now, we have come up with some ideas to modify the recipe of the paste that we would like to evaluate. To do so we first make 50 cookies with the current recipe and count the number of cookies with defective ears and then we do the same thing with the new recipe. In this test we decided on a sample size of 50 cookies for both the current and new recipe but for some reason only 35 cookies were collected for the new recipe. For the current recipe 15 out of 50 cookies had damaged ears and for the new recipe 8 out of 35 were defective
Ok… the collection of samples did not go according to our plans but how will it affect the comparison? We will find out in a short while!
Now to the question we all (or at least the baker) would like to have an answer to:
Is the new recipe better or not?
Well 8/35=0.23 is less than 15/50=0.30 but perhaps we were just lucky this time… some more analysis is needed!
There are a few steps that you need to go through when trying to answer a question like this using a Bayesian framework
- Decide on how to model the data generation process
- Estimate the parameters of the model i.e. obtain a posterior distribution for the parameters
- Use the posterior distribution to make some inference
Ok, let’s start with the first point. There are two possible different outcomes for each cookie, it can be OK or it can be defective. Moreover, there can be at minimum no defective cookies in a sample and at maximum all the cookies can be defective (that would not be good). This sounds very much like a binomial process that has generated the data. Such a model is described by one parameter which we in this example can call the defect rate. This represents the probability that a cookie will be defective.
For the second point we will use Bayes’ rule to get the posterior distribution of the defect rate. Just to refresh the memory here is Bayes’ rule
\[ p(H|D) = \frac{p(H) \cdot p(D|H) }{p(D)} \]
So to estimate the posterior distribution, \( p(H|D)\) we need a prior distribution, \(p(H)\), i.e. what do we believe about the defect rate before we see any data. We also need to specify the likelihood function, \(p(D|H)\), i.e. the probability of getting the data given the hypothesis. We also need the denominator, \(p(D)\), or the normalizing constant. The normalizing constant will ensure that all the hypotheses add up to one (100%).
Now, let’s have a look at the individual components of Bayes’ rule shall we!
In this case we do not have that much information of the prior distribution so let’s use a non-informative one where all hypotheses are equal as likely. Written in code it looks something like this
H = np.arange(0,1.01,0.01) prior_1 = np.ones(len(H)) prior_2 = np.ones(len(H))
That was kind of easy (we had to do some thinking about what prior we should use but when we decided on a non-informative prior at least the coding was easy).
In this previous post on this topic we looked at all the cookies one by one and made a Bayesian update for each cookie. This is perfectly fine but in this blog post we are going to use a more compact way to do the Bayesian update.We are going to use the binomial probability mass function from scipy.stats to define the likelihood function. In general terms, this function takes three input parameters, the sample size,the number of successful outcomes and the probability of a single success. In our case since we are interested in the defect rate, the general term success means defective cookie. Here is how it looks like in code
posterior_1 = prior_1 * sp.stats.binom.pmf(k=15,n=50,p=H) posterior_1 = posterior_1/np.sum(posterior_1) posterior_2 = prior_2 * sp.stats.binom.pmf(k=8,n=35,p=H) posterior_2 = posterior_2/np.sum(posterior_2)
Sweet! What was extremely few lines of code and we have now calculated the posterior distribution for both the current and the new proposed recipe, nice!
The next thing to do is to plot the two posterior distribution in order to get an understanding for how much they differ from each other, let's do that
plt.figure(figsize=(10,7)) plt.plot(H,posterior_1,'b') plt.fill_between(x=H,y1=posterior_1,y2=0,color='b',alpha=0.2,label='Posterior 1') plt.plot(H,posterior_2,'r') plt.fill_between(x=H,y1=posterior_2,y2=0,color='r',alpha=0.2,label='Posterior 2') plt.xlabel('Defect rate [-]') plt.ylabel('Probability [-]') plt.title('Posterior') plt.legend() plt.show()
And the plot
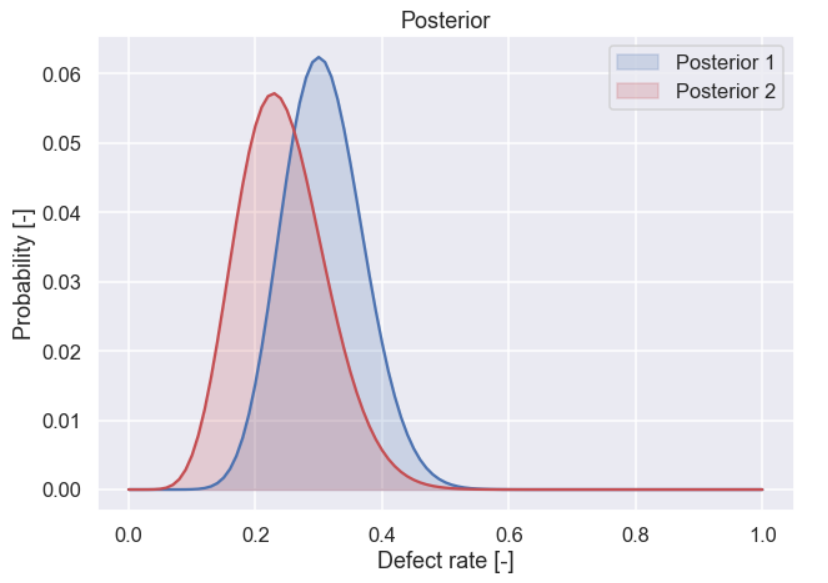
Ok, what can we say about this then? It seems that the current recipe has a higher defect rate since it is shifted to the right when compared to the posterior for the new recipe . However, there is quite a lot of overlap between the two posterior distributions indicating that it is not completely obvious that the new recipe is better than the current one. One final observation is that the posterior distribution for the new recipe is a bit wider than the posterior distribution for the current recipe , this is due to the fact that the sample size for the new recipe is smaller (35 cookies vs 50 cookies) hence more uncertainty.
If we would like to be a bit more quantitative in order to answer the question if the new recipe is better than the current one. One way to do this is to have a look at the difference between the posterior distributions. This is a bit tricky to calculate the difference between two distributions but it can be done by the following steps:
- Create an array containing all possible outcomes, in this case -1 to +1 in steps of 0.01
- For each possible difference, calculate its probability by multiplying the two current values of the posterior distributions
- Sum all contributions
- Normalize the distributions, so it adds up to 1 (100%)
Ok, a bit tricky but let's have a look at the code and it will be a bit more clear.
diff_vector = np.arange(-1,1.01,0.01) prob_vector = np.zeros(len(diff_vector)) for i in range(0,len(H)): for j in range(0,len(H)): d = H[i] - H[j] p = posterior_1[i] * posterior_2[j] prob_vector[np.isclose(diff_vector,d)] += p prob_vector = prob_vector / np.sum(prob_vector)
Super! Let's plot this new distribution.
plt.figure(figsize=(10,7)) plt.plot(diff_vector,prob_vector,'g') plt.fill_between(x=diff_vector,y1=prob_vector,y2=0,color='g',alpha=0.2,label='Posterior 1 - Posterior 2') plt.xlim(-0.5,0.7) plt.xlabel('Difference in defect rate [-]') plt.ylabel('Probability [-]') plt.title('Posterior') plt.legend() plt.show()
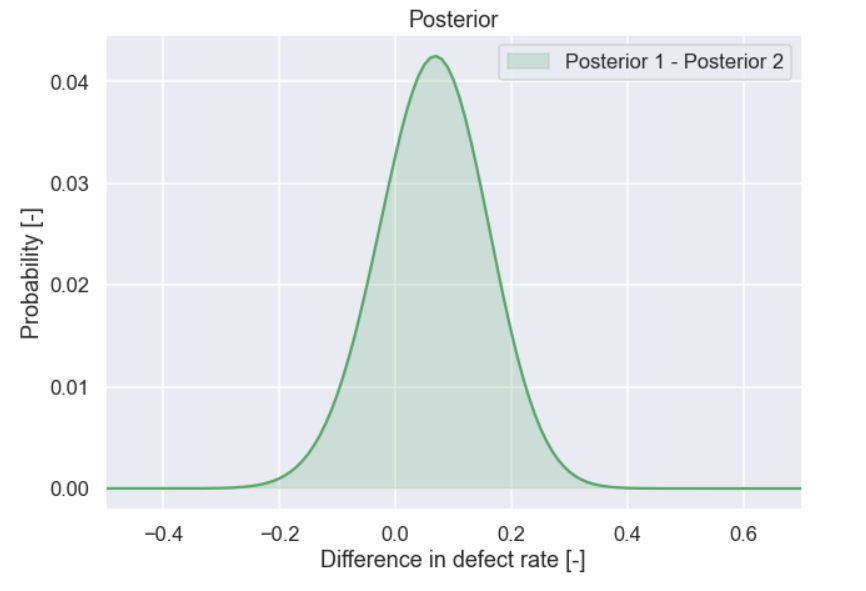
Ok, what does this mean then? The distribution contains both positive and negative values and it is shifted towards the positive side. Since we have calculated the difference between the current recipe and the new recipe a positive number would mean that the new recipe has a lower defect rate than the current one. This is what we are hoping for! So how can we evaluate this then?? Well one idea is to calculate the probability that the new recipe has a lower defect rate than the current one. This can be done by summing up the probabilities with a difference equal to or higher than zero. Before we do this let's plot it.
plt.figure(figsize=(10,7)) plt.plot(diff_vector,prob_vector,'g') plt.fill_between(x=diff_vector[diff_vector<0],y1=prob_vector[diff_vector<0],y2=0,color='r',alpha=0.2,label='Posterior 1 - Posterior 2 < 0') plt.fill_between(x=diff_vector[diff_vector>=0],y1=prob_vector[diff_vector>=0],y2=0,color='g',alpha=0.2,label='Posterior 1 - Posterior 2 >= 0') plt.xlim(-0.5,0.7) plt.xlabel('Difference in defect rate [-]') plt.ylabel('Probability [-]') plt.title('Posterior') plt.legend() plt.show()

Ok, the green area is larger than the red area indicating that the probability that the new recipe is better than the current one is more than 50 %. To be more precise let's calculate the "exact" probability
prob_new_rec_better = np.sum(prob_vector[diff_vector>=0]) prob_new_rec_better
Here we get a value of approx. 77% so we can say that the data we have collected indicates that there is a 77% chance (probability) that the new recipe is better than the current one. Nice!
Just as some examples there are more questions that can be answered from the same distribution, for instance
- What is the most likely difference?
- What is the probability that the new recipe is 10%-units better than the current one?
- What is the probability that the new recipe is 20%-units better than the current one?
Let's answer these questions as well!
max_likelihood_diff = diff_vector[prob_vector==np.max(prob_vector)][0] prob_new_rec_10percent_units_better = np.sum(prob_vector[diff_vector>=0.1]) prob_new_rec_20percent_units_better = np.sum(prob_vector[diff_vector>=0.2]) print('Most likely difference = ' + str(np.round(max_likelihood_diff,3))) print('Probability that new recipe is at least 10%-units better = ' + str(np.round(prob_new_rec_10percent_units_better,3))) print('Probability that new recipe is at least 20%-units better = ' + str(np.round(prob_new_rec_20percent_units_better,3)))
And the output looks like

Really nice!
So we can ask questions about the difference between the defect rate for the two recipes and we can answer them in terms of probabilities. This is often quite intuitive and persons tend to understand these types of results. If we would compare this to the classical null hypothesis testing you formulate a Null hypothesis (and an alternative hypothesis), test the Null hypothesis and get a p-value as an answer (we have looked at this in a previous post). The problem is, at least the experience I have, that people do not always have a clear understanding of what a p-value is. In one way I can understand this, the question that the p-value is answering is perhaps not the first question that pops into your mind when faced with a problem similar to this.
Allright, not too bad! With not that much code we were able to quantify the improvements that could be expected from changing to a new recipe. Awesome!
But wait there's more...
Not so Heavy Cookies
Let's stay at the bakery and investigate a different problem. In this problem we are interested in the weight of cookies that are produced. The boss is a bit worried that too many cookies are too small. The cookie should have a weight of approx. 100g but if the weight is below 90g people tend to complain... and that is not good for business.
So, to investigate this we collect a sample of cookies (taken at random) and in this case the sample size is 16 cookies. The individual weight of these 16 cookies is shown in the plot below
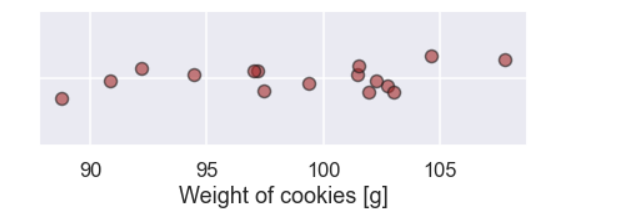
Ok, there are values between say 88g and 109g and perhaps there are more observations near 100g.
So, the question we would like to answer can be formulated something like:
What is the risk that a cookie will have a weight less than 90g?
So, just like the previous problem we start with creating a model for the data generating process and then estimate the parameters (using Bayes' rule). When we have the estimation of the parameters, the posterior distributions, we can start to make some inference.
So... let's think about what kind of process could have generated this data? Here it will be assumed that the weight of cookies can be described or modelled by a normal distribution. It is of course not obvious that is the best choice and it is a modelling decision that you have to make in order to proceed. Now, when we have decided on how to model the data generating process we can start to estimate the parameters. In this specific case we have two different parameters that describe the normal distribution, the mean value and the standard deviation. So these two parameters we need to estimate, We will actually get a posterior distribution for the different pairs of these two parameters.
Let's start with the hypothesis and the prior distribution. Here we will assume that mean values below 70g and above 130g are not possible and the standard deviation can not be larger than 15g (it must be positive). The main purpose of this assumption is to reduce computational time. Since we are using a gridding technique where we evaluate the likelihood function for all possible combinations of the mean and standard deviation the amount of points that needs to be evaluated would be too large if we were interested in a very large span of the two parameters (given the same resolution).
Let's write down the hypothesis and prior distributions in code
H_mean = np.arange(70,130,0.1) H_std = np.arange(0.1,15,0.05) prior_mean = np.ones(len(H_mean)) prior_std = np.ones(len(H_std))
So within the ranges stated above the priors are constant.
Now let's continue with the likelihood function. Similar to the problem with defective cookies that we looked at above, we are going to use some functions available in scipy.stats to define the likelihood function. In this case we are looking for a normal distribution and it is accessed by scipy.stats.norm.pdf().
In the previous example with the defective cookies we "only" had one variable so we had "only" one loop over all the possible hypothesis. In this case we have two parameters so we will need two loops. So for each pair of mean and standard deviation we can calculate the probability to get the data we have collected i.e. \(p(D|H)\). Note that this probability is calculated by multiplying the probability for all measurement points, in this case 16 different weights.
We then just follow Bayes' rule and multiply the likelihood function by the prior distribution for the two parameters and stored in an array, this is the posterior distribution! (a part from a normalizing constant...)
Lots of text here, let's put it into code
mean_vector = [] std_vector = [] posterior_vector = [] for i in range(0,len(H_mean)): for j in range(0,len(H_std)): mean_vector.append(H_mean[i]) std_vector.append(H_std[j]) likelihood = sp.stats.norm.pdf(weight,loc=H_mean[i],scale=H_std[j]) posterior_vector.append( prior_mean[i]*prior_std[j]*np.prod(likelihood*50) ) mean_vector = np.array(mean_vector) std_vector = np.array(std_vector) posterior_vector = np.array(posterior_vector) posterior_vector = posterior_vector / np.sum(posterior_vector)
Nice! Now we have the posterior distribution! Before we visualize the posterior let's try to find the pair of mean and standard deviation that is the most likely one i.e. the pair with the highest probability.
max_idx = np.where(posterior_vector==np.max(posterior_vector))[0][0] print('Most likely mean = ' + str(mean_vector[max_idx])) print('Most likely std = ' + str(std_vector[max_idx]))
and the output is Mean = 98.9g and Std = 5.1g.
Ok, let's try to visualize the posterior distribution. Since we have two parameters, the mean and the standard deviation, it makes sense to use some sort of heat map to show the posterior distribution.
plt.figure(figsize=(8,8)) plt.scatter(mean_vector,std_vector,c=posterior_vector,s=25,cmap='magma') plt.plot(mean_vector[max_idx],std_vector[max_idx],'rx') plt.xlim(94,104) plt.ylim(1,11) plt.xlabel('Mean [g]') plt.ylabel('Std [g]') plt.show()
and the plot
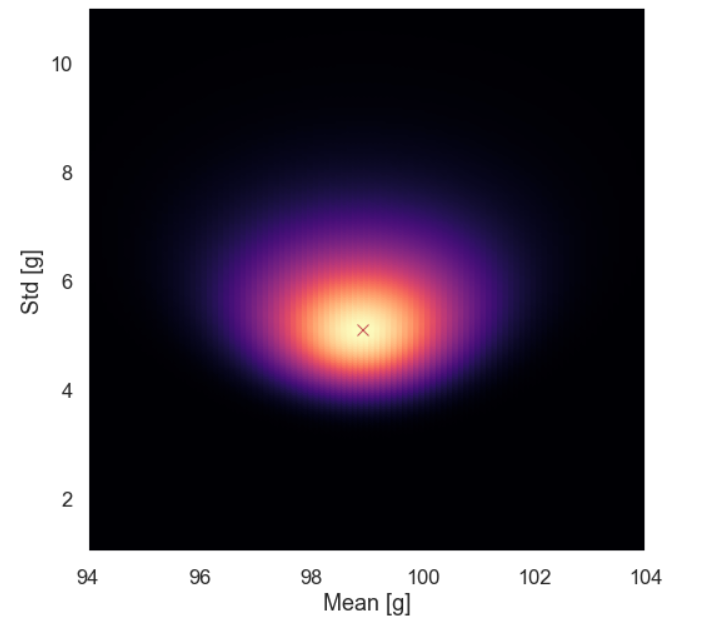
Here the pair (mean and standard deviation) with the largest probability is marked with a red cross. What we can see from the picture is that there is a sort of elliptical blob where the posterior distribution has a higher value. The size of the blob somehow represents the uncertainty of the two parameters, a larger blob means more uncertainty and a smaller one means that we are more certain about the values of our two parameters.
This is perhaps the most "true" way to visualize the posterior distribution since it is, in this case, a function of two parameters. Some additional plots that can be handy is to plot the marginal distribution of the parameters. In this kind of plot you visualize the posterior distribution for one parameter at the time. The marginal distribution for the mean is calculated by the following steps (the procedure is the same for the standard deviation):
- Start with a certain value of the mean (eg 89.4g)
- Find all pair of parameters with this mean value (they will have a lot of different values of the standard deviation)
- Sum all the probabilities for these pairs
- Repeat the steps above for all values of the mean
- Plot the result
In code it would look something like this (including the marginal distribution for the standard deviation)
marginal_prob_mean = np.zeros(len(H_mean)) marginal_prob_std = np.zeros(len(H_std)) for i in range(0,len(H_mean)): marginal_prob_mean[i] = np.sum( posterior_vector[mean_vector==H_mean[i]]) for i in range(0,len(H_std)): marginal_prob_std[i] = np.sum( posterior_vector[std_vector==H_std[i]])
And here are the plots of the two marginal distributions
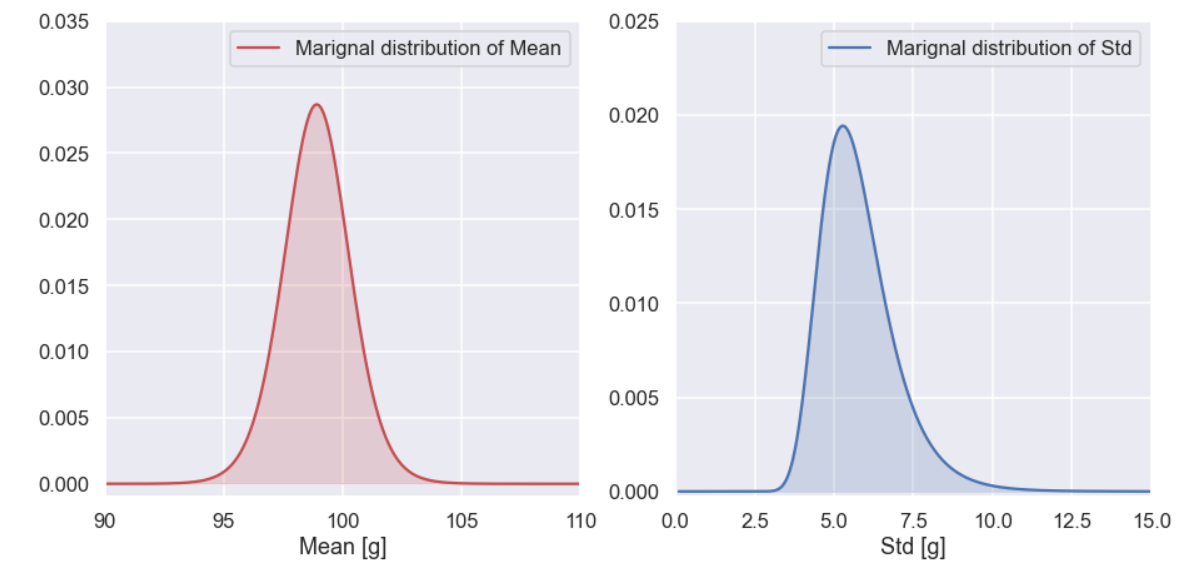
And Voila, the marginal distribution of the mean and the standard deviation. Note that if we would sum up all the probabilities for the marginal distribution of the mean we basically have a sum of the whole posterior distribution which by definition is 1. This is of course true for the marginal distribution of the standard deviation as well.
This is going along quite nicely I would say. I think we now are in a position where we can try to answer the question we asked in the beginning of this example.
What is the risk that a cookie will have a weight less than 90g?
So, how to answer this question... well if we had the "true" values of the mean and the standard deviation we could plot the normal distribution and calculate how much probability that is contained below 90g. Let's do that for the mean and standard deviation with the largest probability
plt.figure(figsize=(10,7)) y = sp.stats.norm.pdf(x,loc=mean_vector[max_idx],scale=std_vector[max_idx]) y = y/np.sum(y) plt.plot(x,y,lw=3,c='r') plt.fill_between(x[x<90],y[x<90],0,color='r',alpha=0.3,label='Probability of weight below 90g') plt.xlabel('Weight [g]') plt.ylabel('Probability [-]') plt.legend() plt.ylim(-0.001,0.05) plt.show()
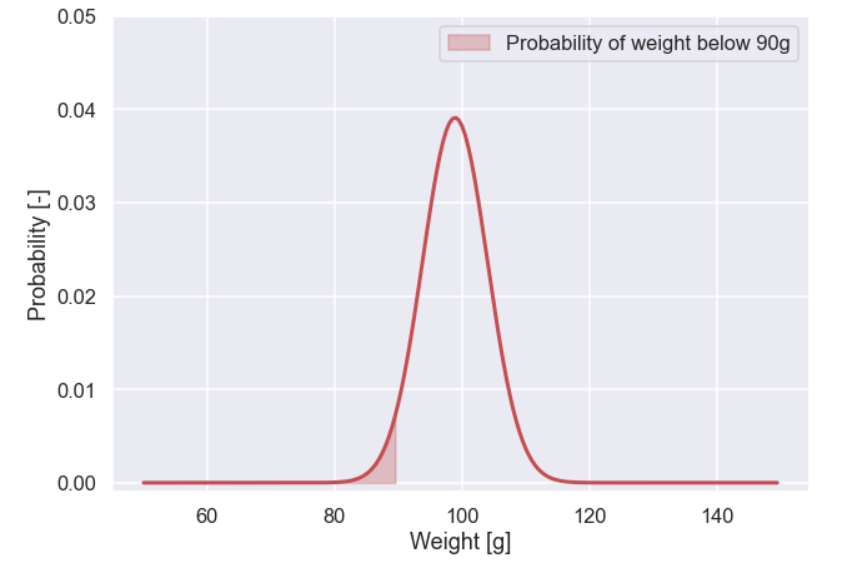
Nice, and to calculate the actual number for the probability to have a cookie with a weight less than 90g we just make a sum off all these points
prob_below_90 = np.sum(y[x<90]) prob_below_90
Ok, the value was approx 0.036 so say a 4% probability that a cookie will have a weight below 90g. Well... this would be ok if we know the true values of the mean and the standard deviation but... we have only measured 16 cookies... so for sure we are not completely certain about the values of the mean and the standard deviation. Moreover, it is clear that both the mean and the standard deviation is important in order to calculate what we are after (the risk of having a cookie with a weight below 90g).
Well, today is your lucky day since we have just calculated the posterior distribution for these parameters! What we can do now is to draw samples from the posterior distribution in accordance with their probability. This can be done by the numpy function random.choise()
rand_idx = np.random.choice(np.arange(0,len(posterior_vector)),p=posterior_vector,size=10000)
So, here we have samples of 10000 different positions in the posterior distribution and each position represents a pair of mean and standard deviation.
Let's plot the normal distribution of some of these pairs.
plt.figure(figsize=(10,7)) x = np.arange(50,150,0.5) for i in rand_idx[0:500]: y = sp.stats.norm.pdf(x,loc=mean_vector[i],scale=std_vector[i]) y = y/np.sum(y) plt.plot(x,y,lw=1,c='k',alpha=0.05) y = sp.stats.norm.pdf(x,loc=mean_vector[max_idx],scale=std_vector[max_idx]) y = y/np.sum(y) plt.plot(x,y,lw=4,c='r',label='Largest probability') plt.xlabel('Weight [g]') plt.ylabel('Probability [-]') plt.legend() plt.show()
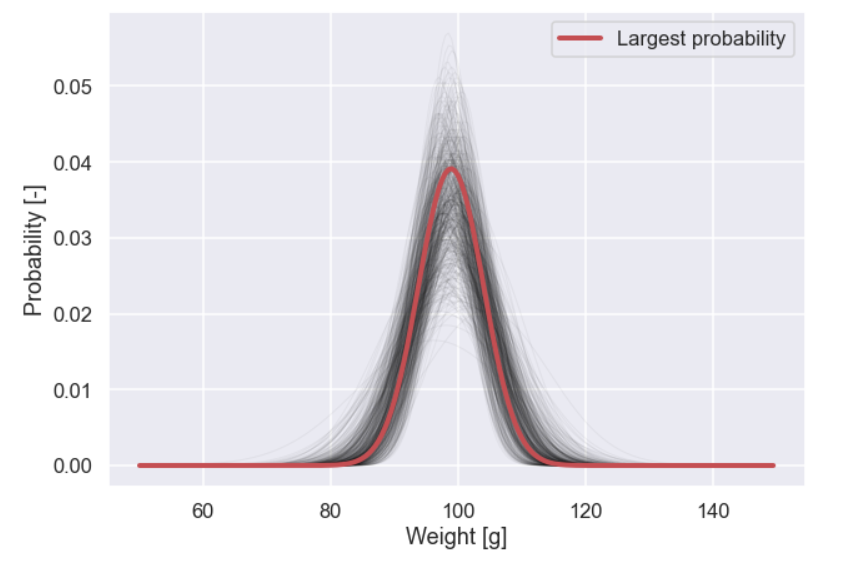
Ok, so now we have a visual representation of the magnitude of uncertainty that we have, awsome!
Now, for each of the pairs of mean and standard deviation we can calculate the risk of having a cookie with a weight below 90g. Let's do this and plot the result in a histogram as well
prob_below_90 = [] for i in rand_idx: y = sp.stats.norm.pdf(x,loc=mean_vector[i],scale=std_vector[i]) y = y/np.sum(y) prob_below_90.append( np.sum(y[x<90]) ) prob_below_90 = np.array(prob_below_90) # Max likelihood estimate y = sp.stats.norm.pdf(x,loc=mean_vector[max_idx],scale=std_vector[max_idx]) y = y/np.sum(y) prob_below_90_ML = np.sum(y[x<90]) plt.figure(figsize=(10,7)) plt.hist(prob_below_90,bins=40,color='k',alpha=0.4) plt.vlines(prob_below_90_ML,0,1250,color='r',lw=5,label='Largest probability') plt.xlabel('Probability of weight below 90g [-]') plt.legend() plt.show()
and, finally, the plot
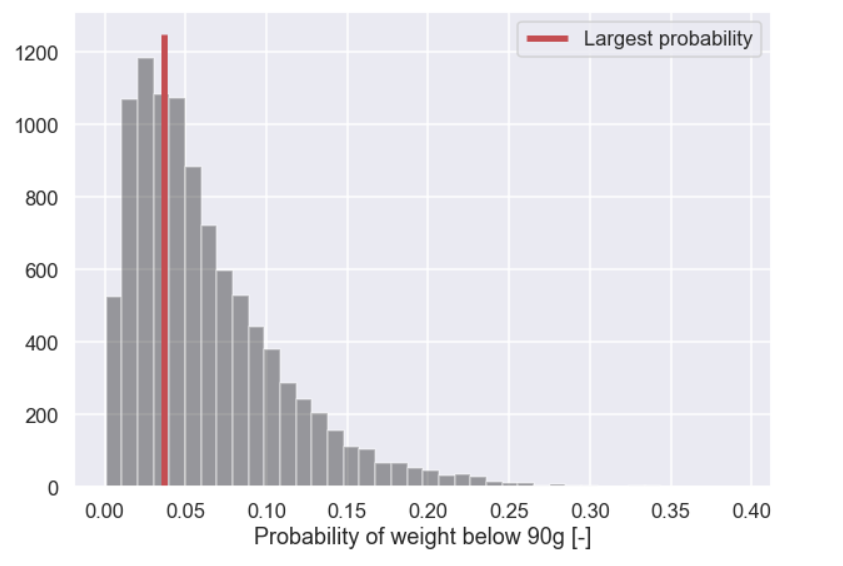
What we can see from the plot above is that even though the most probable value is around 4% there is a quite large tail with higher numbers. To get sort of quantitative lets calculate the probability that the risk of risk for a cookie having a weight below 90g is above 10%
np.mean(prob_below_90>0.10)
and the output is 0.1812, Ok, so there is an almost 20% probability that the risk of a cookie having a weight below 90g is above 10%. Moreover, what is the probability for a risk above 16%?
np.mean(prob_below_90>0.16)
and the output is 0.0477, Ok, this is also interesting! Even though the most likely risk for a cookie having a weight below 90g is approx 4% there is still a 5% probability that this risk is above 16%.
Time to conclude
So what have we learned in this blog post?
In the first example we used the posterior, or rather the difference between two different posteriors, to evaluate if a new recipe could be better than the current one. In the second example ew evaluated the risk of having cookies with low weight. This was done by calculating the posterior distribution and then drawing samples from this posterior. In both of these examples, we could ask very natural questions and get answers in terms of a probability. At least to me these kinds of answers are quite easy to interpret and I think that most people have a rather good idea of what probabilities mean.
So, we have now covered several aspects of Bayesian statistics but there are still more to come. In the next blog post we are going to have a look at how to do Bayesian regression analysis.
As always, feel free to contact us at info@gemello.se