Introduction to Bayesian statistics… part something… In the previous blog posts on Bayesian statistics we have defined a generative model (one that can generate new “fake” data) and then used Bayesian updates to estimate involved parameters. Guess what, we are going to do the same thing here!! In this blog post we are going to look at linear regression i.e. a model that looks at the relation between two (or more) numerical parameters and do it Bayesian style! So, let’s get started.
In this blog we are going to look at an example from the human body but still with some mechanical focus.
The femur, or thigh bone, is the largest and thickest bone in the human body. In this blog post we are going to look at how a parameter of the femur is related to some other parameters. Let’s load some data and have a look at it
df_data = pd.read_csv('Post_25_Bayesian_reg/MulticollinearityExample.csv') df_data.head()
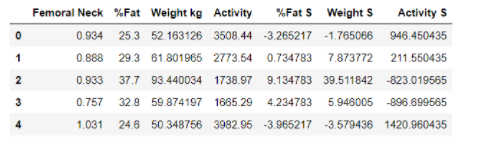
Here each row represents an individual. As this is a post about regression analysis we are interested in the relation between one dependent variable and one or more independent variables. In this blog post we are interested in the first parameter called Femural Neck which represents the bone mineral density of the femoral neck so this will be the dependent variable. As the independent variable we will use the Weight kg parameter i.e. we would like to investigate the relationship between weight and bone mineral density of the femoral neck.
A nice way to get a visual of the relationship is to plot the two variables in a scatter plot. Here we only look at 40 different individuals with a weight below 80kg.
df_data_below_80 = df_data[df_data['Weight kg']<80] x = df_data_below_80.iloc[:40,2].values y = df_data_below_80.iloc[:40,0].values plt.figure(figsize=(10,8)) plt.scatter(x,y,c='r') plt.xlabel('Weight') plt.ylabel('Bone mineral density of the femoral neck') plt.show()
And the scatter plot
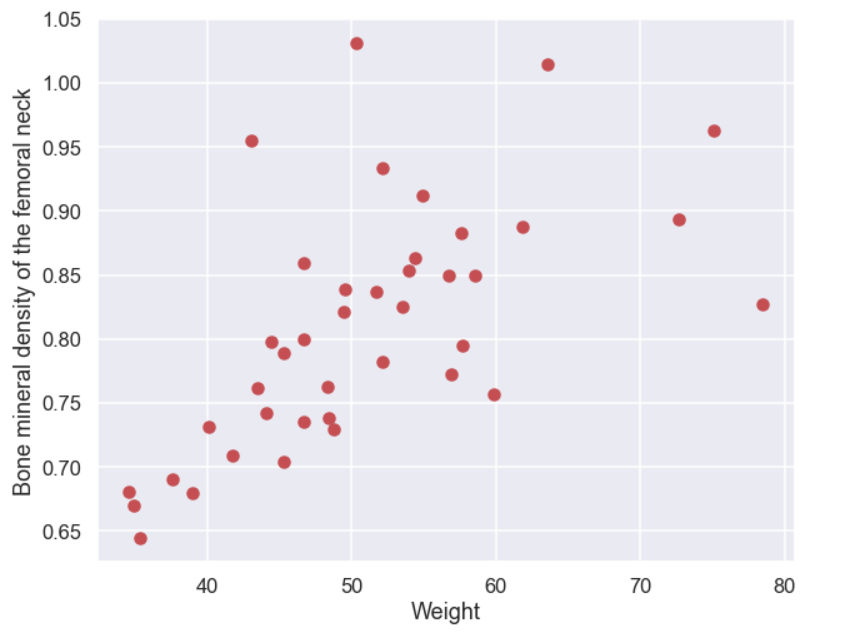
Ok, it might be that there is something going on here. There seems to be a positive relationship between weight and bone mineral density i.e. a heavier person seems to have a higher bone mineral density. Now that we have observed this relationship let’s try to create a (generative) model that the data could have come from.
It is Modelling Time
So… now we need to think… We should come up with a model that could have generated the data. Let’s try to keep it simple and propose something like this:
i.e. the bone mineral density comes from a normal distribution where the mean value,
In this example we have proposed a simple linear relationship between the mean bone mineral density and the weight which is reasonable when looking at the scatterplot above.
In this case the relationship is defined by two parameters,
In a more general case the standard deviation,
It is Estimation Time
Now that we have defined a model that could have generated the data we should estimate the different parameters. In this case we need to estimate three parameters, a and b that are related to the mean value of the bone mineral density as well as sigma that is related to the noise. To do so we use Bayes’ rule just as we have done in the previous posts on this topic and to refresh the memory, let’s have a look at Bayes’ rule again
where the posterior
I think that the likelihood function is the one that needs the most attention in this example but before we look at that a minor adjustment of the data is preferable. Let’s subtract the mean weight from the weight variable so it is sort of centered around 0
x_prim = x - np.mean(x) y_prim = y plt.figure(figsize=(10,7)) plt.scatter(x_prim,y_prim,c='r') plt.xlabel('Normalized Weight') plt.ylabel('Bone mineral density of the femoral neck') plt.show()
And the plot of this adjusted data set would look like this
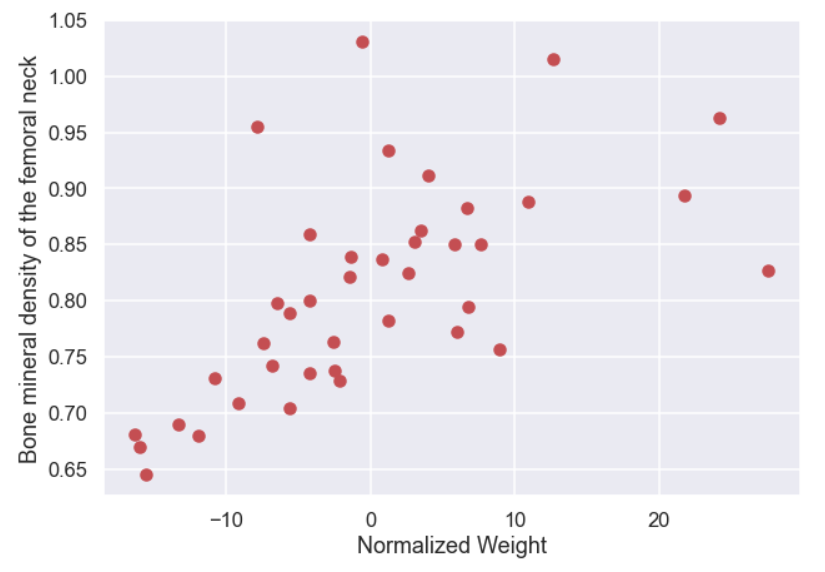
This will make the interpretation of the intercept a little more meaningful as it will represent the average bone mineral density of a person with the mean weight of the data set (51 kg). If we would have used the original data the intercept would represent the mean bone mineral density of a person with a weight of 0 kg… perhaps not that intuitive.. Since we are just shifting the data the slope is not affected so the interpretation of the slope would still be how much does the bone mineral density change for a weight increase of 1 kg. (There can actually be some additional advantages but we are not going into these in this blog post).
Now, let’s return to the likelihood function. As stated above the likelihood function
sp.stats.norm.pdf(y_prim[0],loc=1.0 + 0.1*x_prim[0],scale=0.1)
Here loc represents the mean and scale is the standard deviation.
As you might have guessed, if the actual data point further away from the mean given by the parameters
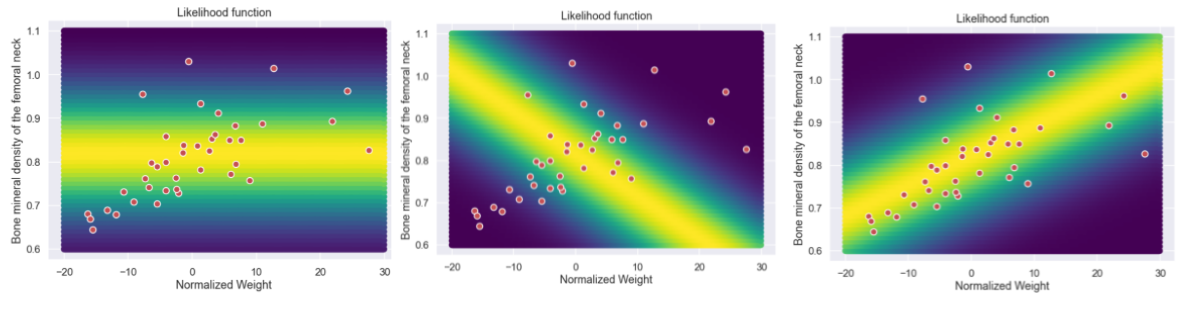
The left plot will give a sort of in the middle value of the likelihood function, the middle one would give a very low value and the right one would give a high value.
So, now that we have talked about the likelihood function let's decide on what kind of priors to use. In this blog post we are going to use the perhaps most simple priors we can think of namely uniform priors. These priors will have a constant value inside some regions and a value of zero everywhere else.
So, Now we are ready to calculate the posterior distribution.
Similar to the previous blog posts on this topic we are going to use a gridding technique to calculate the posterior i.e.
we loop over all possible combinations of the three different parameters (
alpha = np.linspace(0.7,0.9,80) beta = np.linspace(0,0.02,80) sigma = np.linspace(0.01,0.2,80) prior_alpha = np.ones(len(alpha)) prior_beta = np.ones(len(beta)) prior_sigma = np.ones(len(sigma)) prior_alpha = prior_alpha/np.sum(prior_alpha) prior_beta = prior_beta/np.sum(prior_beta) prior_sigma = prior_sigma/np.sum(prior_sigma) alpha_list = [] beta_list = [] sigma_list = [] posterior = [] for i in range(0,len(alpha)): for j in range(0,len(beta)): for k in range(0,len(sigma)): alpha_list.append(alpha[i]) beta_list.append(beta[j]) sigma_list.append(sigma[k]) likelihood = 1 for m in range(0,len(y_prim)): likelihood = likelihood * sp.stats.norm.pdf(y_prim[m],loc=alpha[i]+beta[j]*x_prim[m],scale=sigma[k]) post = prior_alpha[i]*prior_beta[j]*prior_sigma[k]*likelihood posterior.append(post) alpha_list = np.array(alpha_list) beta_list = np.array(beta_list) sigma_list = np.array(sigma_list) posterior = np.array(posterior) posterior = posterior/np.sum(posterior)
Nice! Now we have the posterior distribution of the parameters
marginal_alpha = np.zeros(len(alpha)) marginal_beta = np.zeros(len(beta)) marginal_sigma = np.zeros(len(sigma)) for i in range(0,len(alpha)): marginal_alpha[i] = np.sum(posterior[alpha_list==alpha[i]]) for i in range(0,len(beta)): marginal_beta[i] = np.sum(posterior[beta_list==beta[i]]) for i in range(0,len(sigma)): marginal_sigma[i] = np.sum(posterior[sigma_list==sigma[i]])
Ok, let’s have a look at the marginal distributions for the intercept,
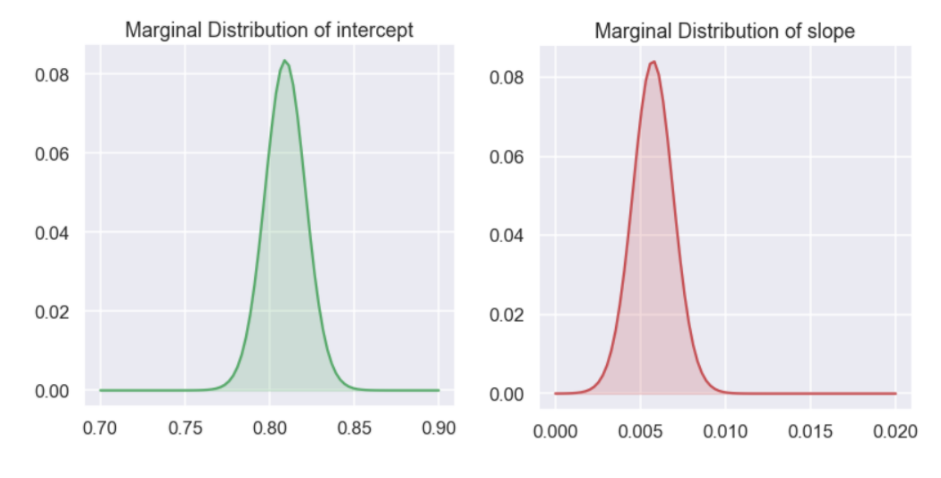
The most probable value of the intercept is just above 0.8 and for the slope is say 0.06.
Moreover, we can say that for the intercept that values below 0.77 are not that probable as well as values above 0.85.
For the slope we are quite certain that it is greater than zero i.e. positive. For completeness,
let’s also have a look at the marginal distribution of the standard deviation
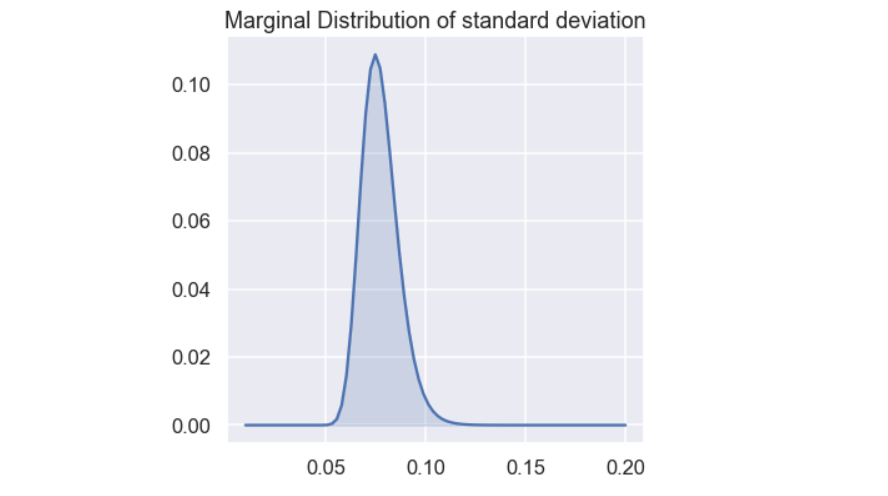
Ok, so a value between say 0.05 and 0.1 is possible and the most probable value is around 0.7.
Just to (hopefully) clarify things a bit. The posterior probability is a function of all three parameters so the marginal distributions of each variable do not show if there is a correlation between the different parameters. Since we have three parameters it is a bit tricky to make a nice looking plot of this but what we can do is to make a plot of, say, the slope and the intercept. This can be done with the following code
alpha_list_2 = [] beta_list_2 = [] marginal_alpha_beta = [] for i in range(0,len(alpha)): for j in range(0,len(beta)): alpha_list_2.append(alpha[i]) beta_list_2.append(beta[j]) marginal_alpha_beta.append( np.sum(posterior[((alpha_list==alpha[i]) & (beta_list==beta[j]) )]) ) plt.figure(figsize=(9,7)) plt.scatter(alpha_list_2,beta_list_2,c=marginal_alpha_beta,s=150,cmap='viridis') plt.colorbar() plt.xlabel('Intercept') plt.ylabel('Slope') plt.show()
And the plot would look like this
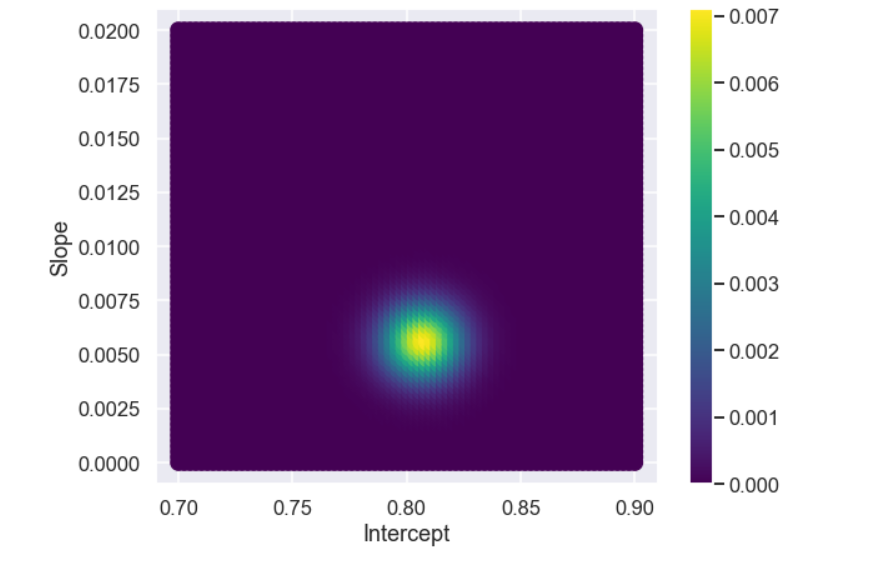
So, in this case there does not seem to be too much correlation between the slope and the intercept.
It is Prediction Time
Now that we have calculated the posterior distribution let’s make some use of it. One interesting question would be, that since we have some uncertainty in the estimation of the slope and intercept, between what values does the mean value most likely exist? Well, what we can do is to draw many values of the three parameters from the posterior and plot each line. Then we can calculate a credible interval by excluding, say the 10% of, the most unlikely values (giving a 90% credible interval). Note that this is done for each value of the normalised weight. Here is some code that do this
x_pred = np.linspace(min(x_prim),max(x_prim),50) idx_vector = np.arange(0,len(posterior)) samples_from_post = np.random.choice(idx_vector,p=posterior,size=100000) posterior_values = np.zeros((len(samples_from_post),len(x_pred))) for i in range(0,len(samples_from_post)): a = alpha_list[samples_from_post[i]] b = beta_list[samples_from_post[i]] posterior_values[i,:] = a + b*x_pred cred_plus = np.percentile(posterior_values,95,axis=0) cred_minus = np.percentile(posterior_values,5,axis=0) max_idx = np.where(posterior==np.max(posterior)) a_max = alpha_list[max_idx] b_max = beta_list[max_idx] e_max = sigma_list[max_idx] plt.figure(figsize=(10,7)) plt.plot(x_pred,cred_plus,'r',lw=1) plt.plot(x_pred,cred_minus,'r',lw=1) plt.fill_between(x_pred,cred_plus,cred_minus,color='r',alpha=0.1,label='90% credible interval') plt.plot(x_pred,a_max + b_max*x_pred,'r',lw=4,label='Best Fit') plt.plot(x_prim,y,'bo',label='Data') plt.xlabel('Normalized Weight') plt.ylabel('Bone mineral density of the femoral neck') plt.legend() plt.show()
And the plot with the 90% credible interval looks like this
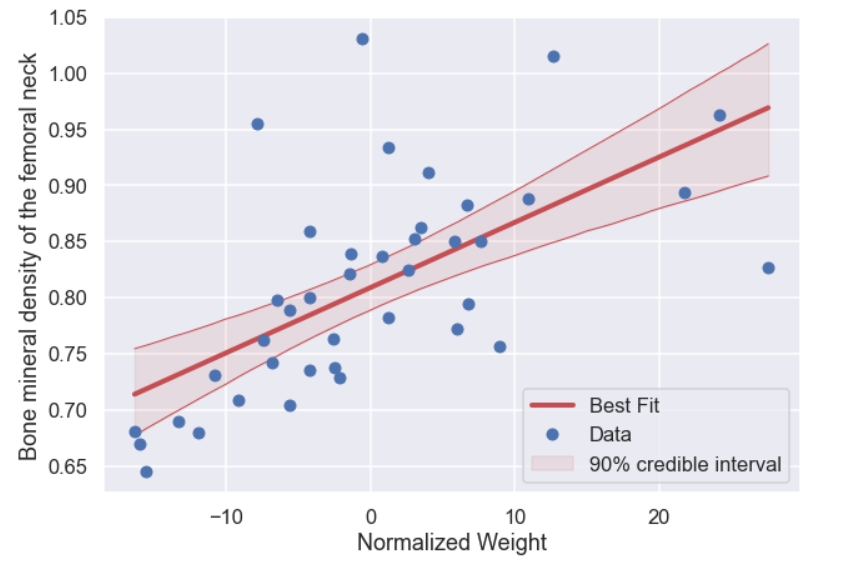
Nice! We can see that we are a bit more uncertain for the higher values of the normalized weight. So if we looked at many persons with a weight 51 kg which corresponds to 0 in the graph above we could say that we are 90% certain that their average bone mineral density will be between 0.79 and 0.83.
But what if I am interested in predicting the bone mineral density of a single person with a weight of 51 kg?
For this we should calculate a prediction interval. We can calculate a prediction interval by a similar approach that we used to calculate
the credible interval but we also include the noise term controlled by the standard deviation
predictive_values = np.zeros((len(samples_from_post),len(x_pred))) for i in range(0,len(samples_from_post)): a = alpha_list[samples_from_post[i]] b = beta_list[samples_from_post[i]] e = sigma_list[samples_from_post[i]] predictive_values[i,:] = a + b*x_pred + np.random.normal(loc=0,scale=e,size=len(x_pred)) predict_plus = np.percentile(predictive_values,95,axis=0) predict_minus = np.percentile(predictive_values,5,axis=0) plt.figure(figsize=(10,8)) plt.plot(x_pred,predict_plus,'b',lw=1) plt.plot(x_pred,predict_minus,'b',lw=1) plt.fill_between(x_pred,predict_plus,predict_minus,color='b',alpha=0.1,label='90% prediction interval') plt.plot(x_pred,a_max + b_max*x_pred,'r',lw=4,label='Best Fit') plt.plot(x_prim,y,'bo',label='Data') plt.xlabel('Normalized Weight') plt.ylabel('Bone mineral density of the femoral neck') plt.legend() plt.show()
and, finally, the plot.
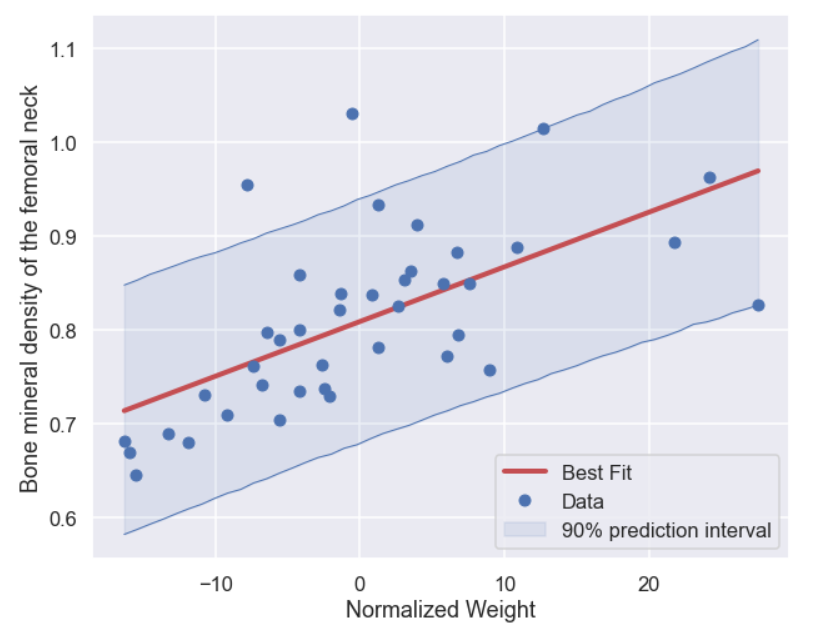
As you see the prediction interval is much wider than the credible interval which is no surprise. For sure we would expect the variation for individuals to be much higher than a summary statistic like the mean.
Time to conclude
Ok, another blog post has come to its end. What I would like to demonstrate with this post is that the procedure of doing Bayesian analysis is quite similar independent of what kind of problem you are trying to solve. If we can come up with a model that could have generated the data we can estimate the involved parameters by using Bayes’ rule.
If you would test to run the code that calculated the posterior distribution you will find that it takes quite some time to run. To be honest, the code is not that optimized so for sure we could do some things in this area.
But there is a bigger problem here….
Since we use a gridding method, adding additional parameters will increase the computational time by a lot! Just as an example if you need 100 points to get decent resolution for one variable we would need 100*100=10 000 points for the same resolution with two different parameters. For three different parameters we would need 100*100*100=1 000 000 points. This is known as the Curse of Dimensionality. So as the number of parameters increases it would be more or less impossible to apply this gridding method since it would take forever.
Luckily there is a solution to this problem and it is called Markov Chain Monte Carlo or MCMC. This method explores the parameter space in a much more intelligent way so we do not need to spend time in areas where the posterior has a very low values. Perhaps in some future posts we can have a look at the MCMC method.
Well that was all for this time! As always, feel free to contact us at info@gemello.se