This is the second blog post on the topic Principal Component Analysis or PCA. In the first blog post the intention was to get a feel for what PCA is, and we used a sort of brute force approach to find the principal components. This was ok since the example that we looked at was not that complicated and only contained two variables. In this blog post we are going to look at a dataset with a higher number of variables (4 to be exact) so the method that we used in the previous blog post will be sort of computationally ineffective. So we should do something else... and this is the topic for this blog post. So let’s look at some data and get going!
The Iris data set
This is a quite “famous” data set which was presented by the well known statistician and biologist Ronald Fisher in a paper from 1936. The data set contains four features related to the geometry of the flower: Sepal length, sepal width, petal length and petal width (all measured in cm). 150 flowers were measured, equally splitted between three different species of iris flowers: Iris setosa, Iris versicolor and Iris virginica

So, we are going to perform a Principal Component Analysis on this data set
By the way, If you are as old as I am you perhaps remember that Iris is a song that was released in 1998 by the American rock band the Goo Goo Dolls
Those were the days...
Anyhow, the Iris data set is available from, for instance, scikit learn and is imported by the following lines of code (together with some other standard imports)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set(context='talk') from sklearn import datasets # import some data to play with iris = datasets.load_iris() X_iris = iris.data[:,:] y_iris = iris.target
To start with let’s just look at the shape of the X_iris variable
X_iris.shape
And the output is (150,4) so 150 different flowers with 4 measurements for each flower. If we look at the variable y_iris it has the size of (150) and contains the species of the flower encoded by the number 0,1 and 2 where 0 = Iris setosa, 1 = Iris versicolor and 2 = Iris virginica.
Before we start to dig deeper into the PCA stuff we should center the data as we did in the last blog post on this topic. This is done by removing the mean value for each variable. Moreover, a good thing to do is also to standardize the measurements by dividing by the standard deviation of each variable. This is done by the following lines of code.
X_iris_stand = np.zeros(np.shape(X_iris)) for i in range(0,4): X_iris_stand[:,i] = (X_iris[:,i] - np.mean(X_iris[:,i])) / np.std(X_iris[:,i])
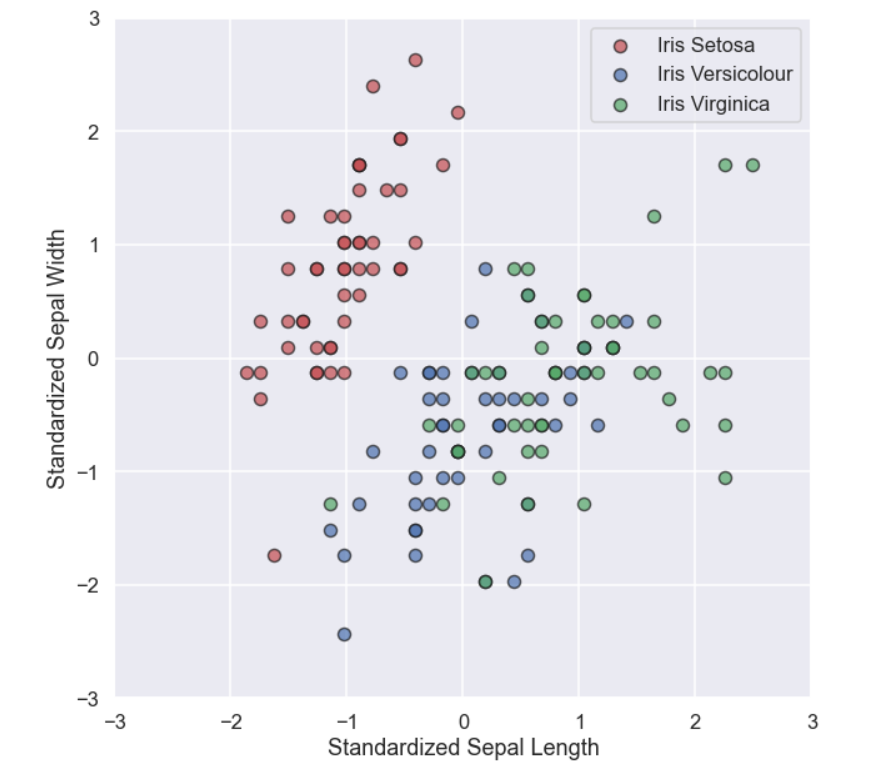
Sweet, now each feature is standardized having a mean of zero and a standard deviation of one. Let’s just plot what the standardized sepal length and sepal width looks like
Iris_type = ['Iris Setosa', 'Iris Versicolour', 'Iris Virginica'] Iris_c = ['r','b','g'] plt.figure(figsize=(10,10)) for i in range(0,3): plt.scatter(X_iris_stand[y_iris==i,0],X_iris_stand[y_iris==i,1], c=Iris_c[i],edgecolor='k',label=Iris_type[i],s=100,alpha=0.7) plt.legend() plt.xlabel('Standardized Sepal Length') plt.ylabel('Standardized Sepal Width') plt.xlim(-3,3) plt.ylim(-3,3) plt.show()
and the plot
PCA a different way
Now let’s start with some PCA stuff!
What we did in the previous blog post was to use a sort of brute force method to find the directions with the largest variance. After that we did a new search with an additional condition that this second direction must be orthogonal to the first one. This goes on until we have found all directions and there are as many directions as there are variables. This was ok for the small example that we investigated in the previous blog post where we “only” had two features. In the situation that we are now, where we have four features, this approach will be computationally demanding so:
Is there any alternative way to calculate these directions?
Well, yes there is!
The only small drawback is that we need to remember some stuff from linear algebra, but have no fear!
First of all,let’s just look at the matrix that contains out variables
\[ \bf{X}' = \begin{bmatrix} \bf{x}'_1 & \bf{x}'_2 & \bf{x}'_3 & \bf{x}'_4 \end{bmatrix} \]
Remember that we have used the standardized variables so the mean of each column, \({\bf x'}_i\) , is 0 and the stand deviation is 1. Now, let’s define a new matrix
\[ {\bf C} = \frac{1}{n-1} {\bf X}'^T \cdot {\bf X}' \]
Here T represents the transpose (switching rows with columns). Ok, what is this… Let’s have a look at \( {\bf C}\) for our example with four variables
\[ {\bf C} = \frac{1}{n-1} \begin{bmatrix} \bf{x'}_{1}^{T} \cdot \bf{x'}_{1} & \bf{x'}_{1}^{T} \cdot \bf{x'}_{2} & \bf{x'}_{1}^{T} \cdot \bf{x'}_{3} & \bf{x'}_{1}^{T} \cdot \bf{x'}_{4} \\ \bf{x'}_{2}^{T} \cdot \bf{x'}_{1} & \bf{x'}_{2}^{T} \cdot \bf{x'}_{2} & \bf{x'}_{2}^{T} \cdot \bf{x'}_{3} & \bf{x'}_{2}^{T} \cdot \bf{x'}_{4} \\ \bf{x'}_{3}^{T} \cdot \bf{x'}_{1} & \bf{x'}_{3}^{T} \cdot \bf{x'}_{2} & \bf{x'}_{3}^{T} \cdot \bf{x'}_{3} & \bf{x'}_{3}^{T} \cdot \bf{x'}_{4} \\ \bf{x'}_{4}^{T} \cdot \bf{x'}_{1} & \bf{x'}_{4}^{T} \cdot \bf{x'}_{2} & \bf{x'}_{4}^{T} \cdot \bf{x'}_{3} & \bf{x'}_{4}^{T} \cdot \bf{x'}_{4} \\ \end{bmatrix} \]
So, it is a 4x4 matrix with . Let’s look at the top left term
\[\frac{1}{n-1} {\bf x'}_{1}^{T} \cdot {\bf x'}_{1} = \frac{1}{n-1} \sum{ x'_{1i} x'_{1i} } \]
Hmm, this looks very familiar… It is the variance of \({\bf x'}_1\)… nice! and the bottom right term
\[\frac{1}{n-1} {\bf x'}_{4}^{T} \cdot {\bf x'}_{4} = \frac{1}{n-1} \sum{ x'_{4i} x'_{4i} } \]
ok this is the variance of \({\bf x'}_4\). At a closer look it turns out that along the diagonal of the matrix we have the variance of each variable. Now let’s have a look at the second term on the top row
\[ \frac{1}{n-1} {\bf x'}_1^T \cdot {\bf x'}_{2} = \frac{1}{n-1} \sum{ x'_{1i} x'_{2i} } \]
This is not the variance since it involves both \({\bf x'}_1\) and \({\bf x'}_2\), it is something called the covariance. Covariance tells you something about how two variables are related to each other. A positive covariance means that when one variable is increasing in value the other variable does the same and a negative covariance means the opposite. A value that is close to zero would indicate that there is no (linear) relationship between the two variables.
Just for a short summary of what we have seen up to this point. The terms in the diagonal of the matrix are the variances for each variable and the off-diagonal terms are the covariance between the different variables. One more thing to notice is that this matrix is always symmetric since the covariance of \({\bf x'}_1\) and \({\bf x'}_2\) is the same as the covariance of \({\bf x'}_2\) and \({\bf x'}_1\).
So, does this matrix have a special name? Well of course! It has a very descriptive name and it is called the covariance matrix. Let’s plug in some numbers and calculate the covariance matrix for our data. First some code
cov_matrix = np.dot(X_iris_stand.T,X_iris_stand) / ((X_iris_stand.shape[0]-1))
then let’s visualize the result in a heat map
plt.figure(figsize=(10,8)) sns.heatmap(cov_matrix,annot=True,vmin=-1,vmax=1,linewidths=1,cmap='bwr') plt.xticks([0.5,1.5,2.5,3.5],['Sepal Length', 'Sepal Width', 'Petal Length' , 'Petal Width']) plt.yticks([0.1,1.1,2.1,3.1],['Sepal Length', 'Sepal Width', 'Petal Length' , 'Petal Width']) plt.title('Covariance Matrix') plt.show()
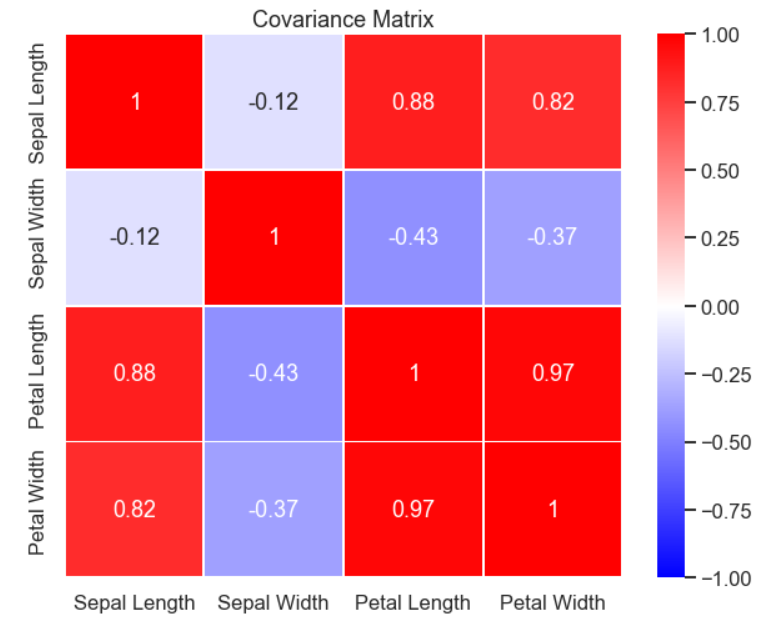
What got my attention here are some really high values of the covariance between some of the features, for instance the petal length and petal width.
Now that we have defined this matrix, how can it be used to find the principal components? Well, as discussed above we would like to find directions where we have large variances. But, as we also saw in the last blog post on PCA, we would like to have as small covariance as possible between the different variables. So what we are looking for is a transformation that makes the covariance matrix diagonal i.e. all the off diagonal terms (covariance terms) are zero or very close to zero. Moreover, the transformation should not alter the data so the transformation must be orthonormal (you can think of this as just a rotation of a coordinate system)
So, how can this be done? This is where things from linear algebra come in handy. We will not go into the details from linear algebra in this blog post but if you like you can have a look at this wikipedia site. Since the covariance matrix is symmetric (and doesn't have any complex numbers) let’s focus on this. The important stuff is going to be eigenvectors and eigenvalues. As you might remember from a linear algebra course an eigenvector, let’s call it \({\bf w}_i\), is a (unit) vector that satisfies the following relation
\[ {\bf A} \cdot {\bf w}_i = \lambda_i {\bf w}_i \]
where A is a symmetric (real) square matrix. So if you multiply the matrix A by one of its eigenvectors you will get back the same vector but scaled with a number, \(\lambda_i\), which is called an eigenvalue. Note that there is an index on the eigenvector and eigenvalue, this since there are several of them. In fact there are n different eigenvectors for an A matrix of size nxn.
So here comes the fun part: A (real) symmetric matrix is always orthogonally diagonalizable according to this relation
\[ \bf{D} = \bf{U}^T \cdot \bf{A} \cdot \bf{U} \]
where \(\bf{D}\) is a diagonal matrix with each eigenvalue along the diagonal and \(\bf{U}\) is a square matrix where each column is an eigenvector. Moreover, all eigenvectors are orthogonal to each other.
So if we calculate the eigenvalues and eigenvectors of the covariance matrix we are pretty much done with the Principal Component Analysis, sweet!
The good part about this is that there are functions in python that directly calculate the eigenvalues and eigenvectors. Let’s use the numpy function linalg.eig to calculate the principal components for our data.
eig_vals, eig_vecs = np.linalg.eig(cov_matrix)
Well, that was quick and easy! Now, let’s look at the eigenvalues which represent the variance for the new directions. They are ordered from the largest to the smallest so the first eigrénvalue is the largest one i.e. A common way to visualize this is to normalize each eigenvalue by the sum of all eigenvalues so they represent a fraction of the total variance. This can then be plotted in a graph like the one below, often called a scree plot.
plt.figure(figsize=(13,6)) plt.bar(x=[1,2,3,4],height=eig_vals/np.sum(eig_vals),label='Individual explained variance') plt.plot([1,2,3,4],np.cumsum(eig_vals) / np.sum(eig_vals),'r',label='Cumulative explained variance') plt.xticks([1,2,3,4]) plt.title('Scree plot') plt.xlabel('# Eigenvalue') plt.ylabel('Fraction of total Variance') plt.legend() plt.show()
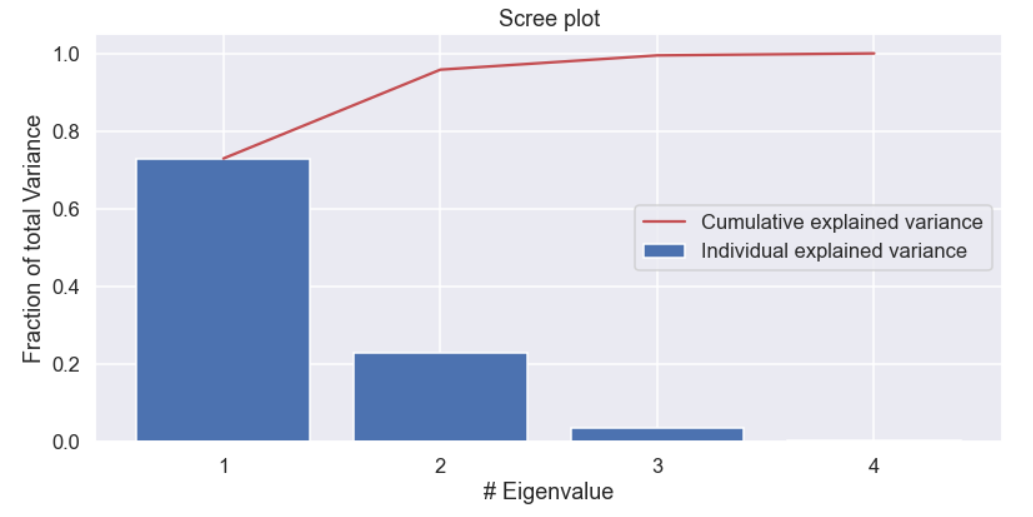
According to the scree plot above, if we include the two first principal components we preserve 96% of the variance in the data set i.e. we only "lose" 4%. So we have been able to reduce the dimension of the data from four down to two features and only lost 4 % of the total variance. This is really nice and it is one of the things that PCA is often used for: to do dimensionality reduction.
The good part about this is that it is much easier to plot the data in two dimensions compared to four dimensions so let’s do this. To be able to plot the data set in the “new directions” we only have to project the data points onto the two first eigenvectors, this can be done using the numpy function numpy.dot(). Some code and a plot
val_PCA_1 = np.dot(X_iris_stand,eig_vecs[:,0]) val_PCA_2 = np.dot(X_iris_stand,eig_vecs[:,1]) plt.figure(figsize=(10,10)) for i in range(0,3): plt.scatter(val_PCA_1[y_iris==i],val_PCA_2[y_iris==i], c=Iris_c[i],edgecolor='k',label=Iris_type[i],s=100,alpha=0.7) plt.legend() plt.xlabel('PCA 1') plt.ylabel('PCA 2') plt.title('Score Plot') plt.xlim(-3,3) plt.ylim(-3,3) plt.show()
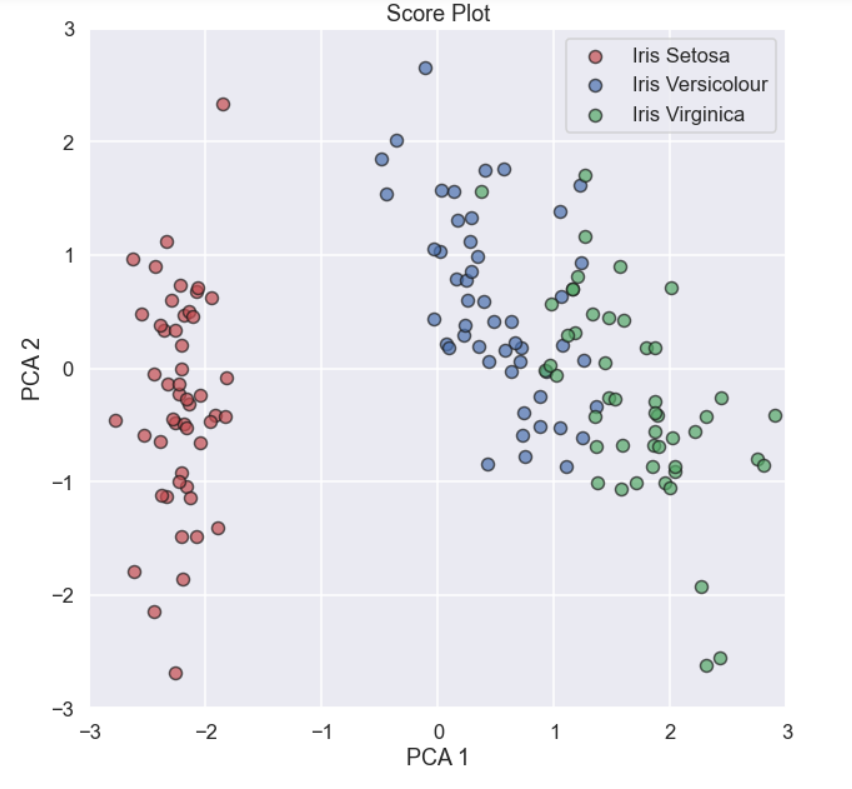
This is often called a score plot.
One final plot that can be of interest is what is called a loading plot. This will highlight the relation between the original 4 features and the principal components (in this case the two first principal components). Here is some code that do this
plt.figure(figsize=(10,10)) plt.arrow(0, 0, eig_vecs[0,0], eig_vecs[0,1], head_width=0.05, head_length=0.1, fc='k', ec='k',length_includes_head=True) plt.text(eig_vecs[0,0], eig_vecs[0,1],'Sepal Length') plt.arrow(0, 0, eig_vecs[1,0], eig_vecs[1,1], head_width=0.05, head_length=0.1, fc='k', ec='k',length_includes_head=True) plt.text(eig_vecs[1,0]+0.05, eig_vecs[1,1]-0.1,'Sepal Width') plt.arrow(0, 0, eig_vecs[2,0], eig_vecs[2,1], head_width=0.05, head_length=0.1, fc='k', ec='k',length_includes_head=True) plt.text(eig_vecs[2,0]+0.1, eig_vecs[2,1]+0.0,'Petal Length') plt.arrow(0, 0, eig_vecs[3,0], eig_vecs[3,1], head_width=0.05, head_length=0.1, fc='k', ec='k',length_includes_head=True) plt.text(eig_vecs[3,0]+0.1, eig_vecs[3,1]-0.1,'Petal Width') plt.title('Loading Plot') plt.xlabel('PCA 1') plt.ylabel('PCA 2') plt.xlim(-1.5,1.5) plt.ylim(-1.5,1.5) plt.show()
and the plot
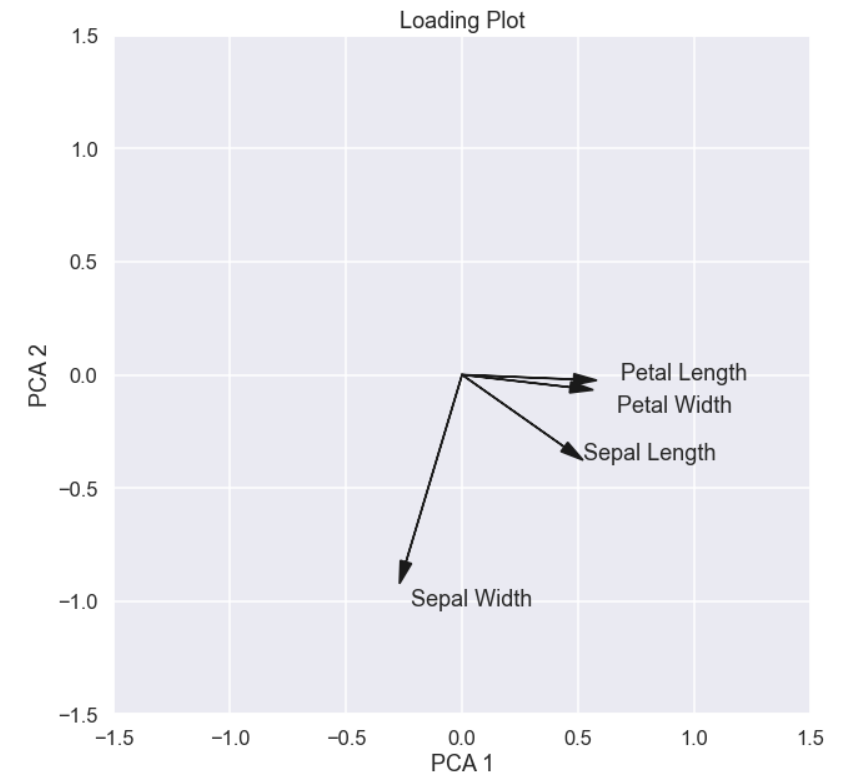
What we can see from here is that the first principal component is related to the sepal length, petal length and petal width in a positive way and approximately by the same magnitude. The sepal width has a negative relation to the first principal component. When it comes to the second principal component it seems to be strongly,negatively, dependent on sepal width. Moreover, there is a very weak relationship between the second principal component and petal length and petal width.
Time to conclude
So, what have we learned in this blog post on PCA? Well, if you know how to calculate eigenvalues and eigenvectors of the covariance matrix you have pretty much cracked it! We have also seen the perhaps most common use of PCA which is dimensionality reduction. The idea is that we can reduce the number of features and still keep much of the total variance in the data set. And, finally, some different types of plots, the scree plot, the score plot and the loading plot was shown. Awesome!
In the next blog post on this topic we are going to use the tools available from scikit learn to analyse a more advanced (well... perhaps not that advanced) data set. Stay tuned!
Well that was all for this time! As always, feel free to contact us at info@gemello.se