So, this is the third and (for now) final blog post on Principal component analysis or PCA. In this first and second blog we looked at the basic concepts and some of the math behind PCA and in this blog post we are going to focus a bit more on what PCA can be used for.
Let’s get to it!!
Let's look at the numbers
Now, let’s have a look at a sort of real example, images of handwritten digits. Scikit learn comes with a data set containing a (huge) number of handwritten digits and we can find them by this few lines of code
import numpy as np import scipy as sp import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_digits digits = load_digits() X_dig = digits.data y_dig = digits.target print(X_dig.shape)
and the print statment returns (1797,64). The X variable contains the actual “image” of the handwritten digits. As can be seen by the shape of the array, it contains approx. 1800 pictures where each picture is represented by 64 variables i.e. it has a resolution of 8x8 pixels. The y variable contains information about what number each sample represents (0-9). Let’s plot the 10 first digits.
plt.figure(figsize=(20,2)) for ii in range(1,11): plt.subplot(1,10,ii) plt.imshow(X_dig[ii-1].reshape((8,8)),cmap='gray_r') plt.grid() plt.axis('off') plt.show()
and the plot
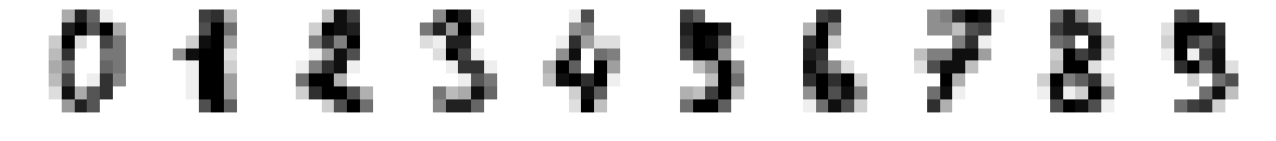
Here we just made a reshape of the data in order to plot it (from 64x1 to 8x8)
Now, we can view each pixel value as an individual variable so each sample (digit) is represented by 64 variables. In the fist blog post we plotted some 2D data in a scatter plot where each sample was represented by a dot in a 2 dimensional space, this since we had two different variables. It would be nice to do the same thing here! The only problem is that we have to make a graph in a 64 dimensional space, and that is hard to do…..
So, it is here that PCA comes into the picture, we are going to use PCA to do dimensionality reduction!
PCA the easy way
To start, let’s calculate the principal components. We will use a “really simple way” to calculate the principal components by utilizing the PCA class that comes with scikit learn. It is done like this:
from sklearn.decomposition import PCA pca = PCA(64) projected = pca.fit_transform(X_dig) print(projected.shape)
and the print statement gives an output of (1797,64) That was quick! Here we have calculated all 64 principal components (as can be seen by the shape of the new array) so we have not done the dimensionality reduction yet. The principal components are sorted in ascending order so starting with the largest component and then they get smaller and smaller. The idea, or at least an assumption, is that directions with larger variance are more important than directions with smaller variance, so let’s start by looking at at plot of the data using the first and second principal components
plt.figure(figsize=(14,10)) plt.scatter(projected[:, 0], projected[:, 1], c=y_dig, edgecolor='none', alpha=0.5,cmap='tab10',vmin=0,vmax=9) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.colorbar() plt.show()
and the plot.
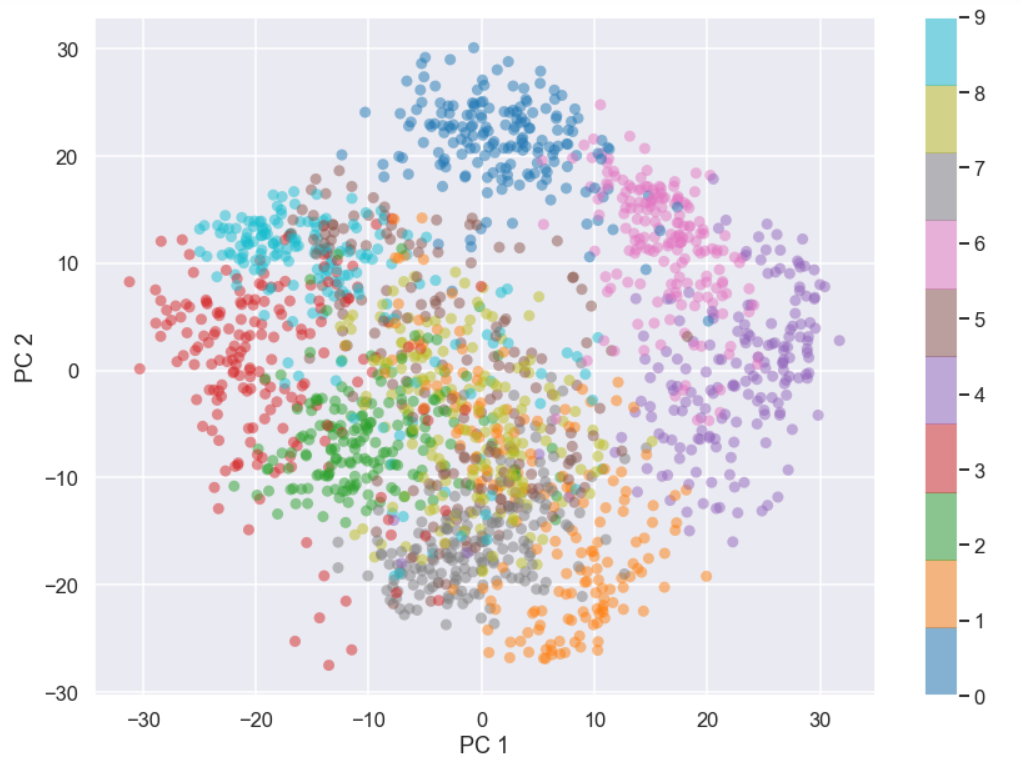
Before discussing the plot let’s just remind ourselves what we have just done. We have calculated the directions with the largest and the second largest variance and projected all data points (digits) on each one of them. The projected values along these directions are then shown in the plot above. So, what do you see here
We see that some of the different clusters are located far away from each other like the points belonging to the digits 0, 3, 4 and 7. Let’s have a closer look at these.
index_dig_plot = ((y_dig==7)|(y_dig==0) | (y_dig==3) | (y_dig==4)) plt.figure(figsize=(14,10)) plt.scatter(projected[:, 0], projected[:, 1], c=y_dig, edgecolor='none', alpha=0.1,cmap='tab10',vmin=0,vmax=9) plt.scatter(projected[index_dig_plot, 0], projected[index_dig_plot, 1], c=y_dig[index_dig_plot], edgecolor='none', alpha=1.0,cmap='tab10',vmin=0,vmax=9) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.colorbar() plt.show()
and the plot
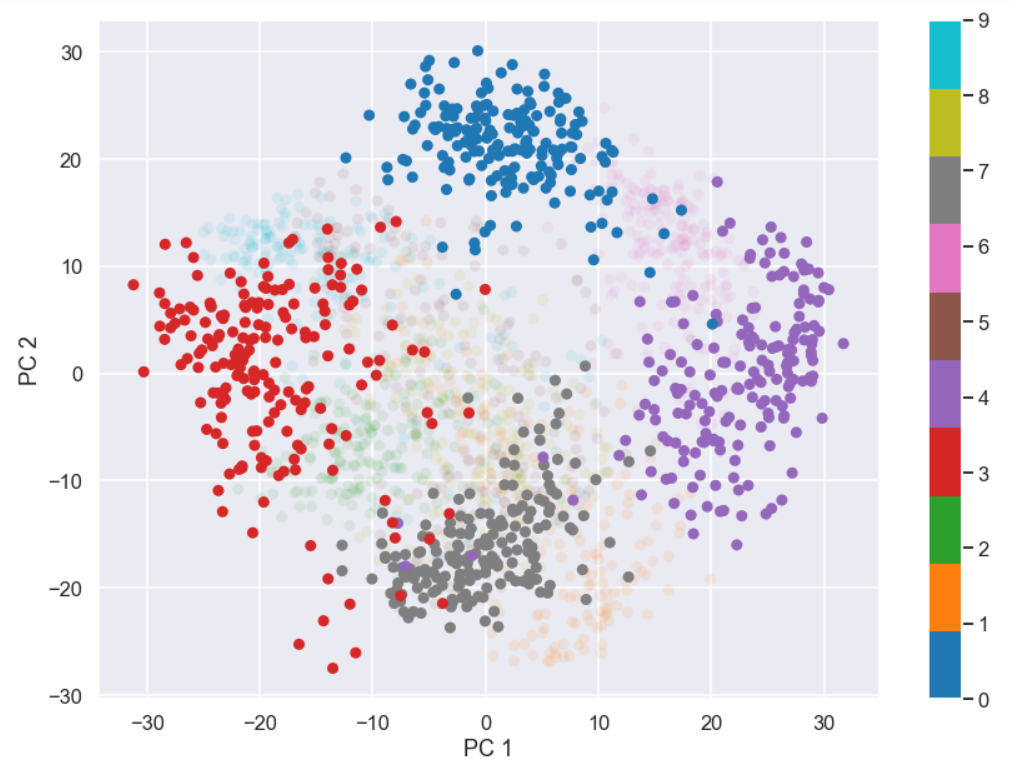
Ok, we have some separation between these four different digent when using only two principal components, nice!. However, this sort of nice separation is not present for all digits, let’s do the same thing as above but look at the digits representing 5,8 and 9
index_dig_plot = ((y_dig==5)|(y_dig==8)|(y_dig==9) ) plt.figure(figsize=(14,10)) plt.scatter(projected[:, 0], projected[:, 1], c=y_dig, edgecolor='none', alpha=0.1,cmap='tab10',vmin=0,vmax=9) plt.scatter(projected[index_dig_plot, 0], projected[index_dig_plot, 1], c=y_dig[index_dig_plot], edgecolor='none', alpha=1.0,cmap='tab10',vmin=0,vmax=9) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.colorbar() plt.show()
and this plot looks like this
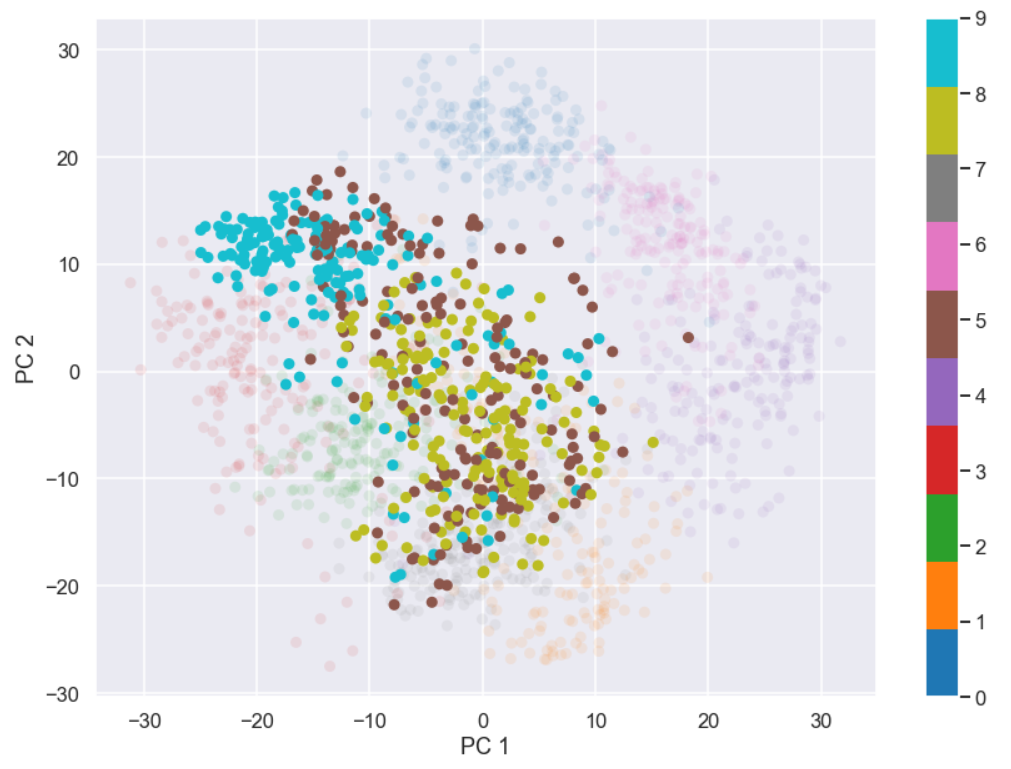
So using only the two first principal components is not enough to separate these digits from each other.
Well, if looking at the first two principal components is perhaps not enough, how many should you then use? Well, I guess that there is no straightforward answer to this but there are some things that you can look at. For instance you can have a look at how much of the total variance that is included by looking at a reduced number of principal components. This can be done by looking at a plot of the cumulative fraction of variance. Let’s do that
plt.figure(figsize=(10,7)) plt.plot(np.arange(0,len(pca.explained_variance_ratio_)),np.cumsum(pca.explained_variance_ratio_),color='r') plt.xlabel('Nr principal components') plt.ylabel('Explained variance') plt.show()
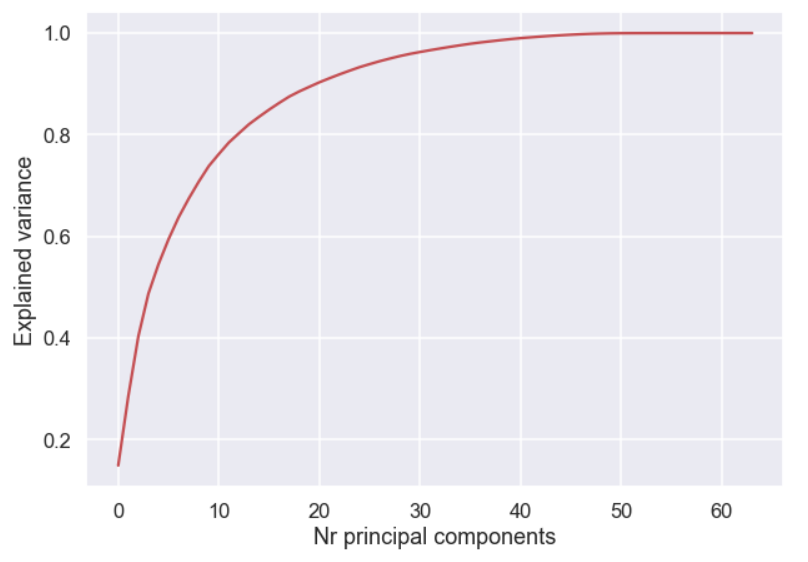
So, it seems that we are catching approx 90% of the total variance by including the first 20 principal components. If we only include 10 principal components we capture just below 80% of the total variance, not too bad
It is perhaps also be interesting to have a look at the directions so let’s do that
plt.figure(figsize=(10,10)) for ii in range(1,65): plt.subplot(8,8,ii) plt.imshow(pca.components_[ii-1].reshape(8,8),cmap='gray_r') plt.text(4.5,7,str(ii),c='magenta') plt.grid() plt.axis('off') plt.show()
and the (busy) plot

So the first, say, 20 directions look something like shapes that can be used to describe digits. The last 20 or so looks just like noise to me.
As you may remember from the last blog post we saw that the principal components were orthogonal to each other. Just to be sure, let’s check if that is true! We can check this by taking the scalar product between all of the 64 directions, this is done by the numpy function np.dot()
plt.figure(figsize=(10,8)) plt.imshow(np.dot(pca.components_,np.transpose(pca.components_) ),cmap='viridis') plt.colorbar() plt.grid()
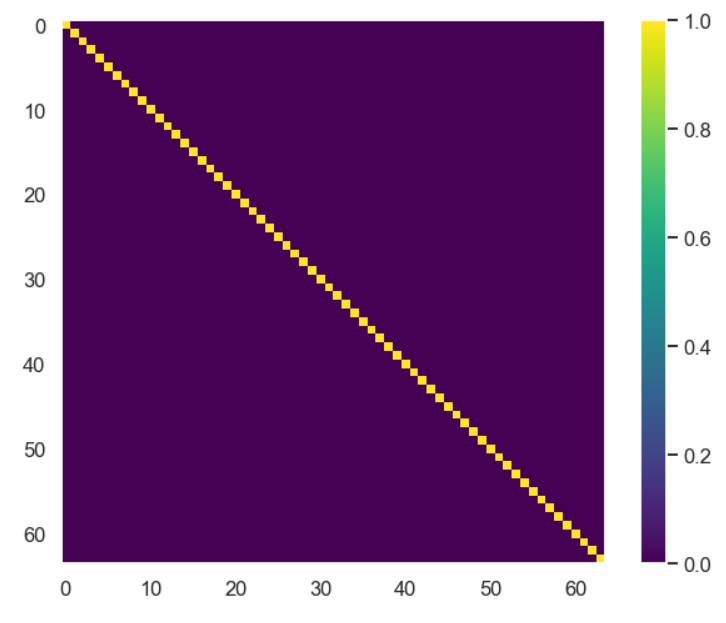
From the picture above we see that when a direction of a principal component is scalar multiplied by itself the result is 1 (since we have unit vectors). If taking a scalar product between two different directions the result is 0 (i.e. they are orthogonal). Sweet!!
So it seems that if we keep the first 20 components (skipping 44 components) and still keep much of the information.
Let’s do one more thing. A vector can always be written as
\[{\bf v} = x_1 \cdot {\bf e}_1 + x_2 \cdot {\bf e}_2 + x_3 \cdot {\bf e}_3 ... + x_n \cdot {\bf e}_n \]
where \({\bf e}_i\) denotes some basis (directions) that are linearly independent. So let’s use the principal directions as the different basis! We get the scalar belonging to each basis by projecting a specific image (digit) onto the basis and this we can do by a scalar product.
Let’s do this for 10 different images and let’s use an increasing number of principal directions, starting with just 2 and ending with all 64. The code looks something like this
nr_comp_vector = [2,8,16,24,32,64] X_dig_prim = X_dig-np.mean(digits.data,axis=0) plt.figure(figsize=(20,16)) sub_plot_nr = 1 for nr_comp in nr_comp_vector: for ii in range(0,10): digit_reduction = np.mean(X_dig,axis=0) for j in range(0,nr_comp): digit_reduction = digit_reduction + np.dot(X_dig_prim[ii],pca.components_[j]) * pca.components_[j] plt.subplot(8,10,sub_plot_nr) plt.imshow(digit_reduction.reshape((8,8)),cmap='gray_r') plt.grid() plt.axis('off') sub_plot_nr = sub_plot_nr + 1 plt.show()
and the plot

If we only used two components you see the very same thing that we saw in the scatter plot above with the first and second principal components. Some digits are quite easy to distinguish but some look more or less the same. For instance, using only two components it is really hard to see any difference between the image of a 3 and the image of a 5. However, already at 16 components it is quite easy to distinguish the different digits from each other.
PCA as noise reduction
Ok, we have seen and discussed how PCA can be used for dimensionality reduction. This means that we can use a reduced number of variables and still keep much of the important stuff. One sort of side effect of this is that if the pictures are a bit noisy, i.e. there is some (small) random noise added to the picture, the important stuff (that has a higher variance than the noise) will not be affected. This will (hopefully) mean that the noise will end up in principal components associated with small variance and can then be filtered out.
Let’s give it a try!
First we add some noise to the pictures
noisy = np.random.normal(loc=X_dig, scale=2) plt.figure(figsize=(20,2)) for ii in range(1,11): plt.subplot(1,10,ii) plt.imshow(noisy[ii-1].reshape((8,8)),cmap='gray_r') plt.grid() plt.axis('off') plt.show()
and the plot
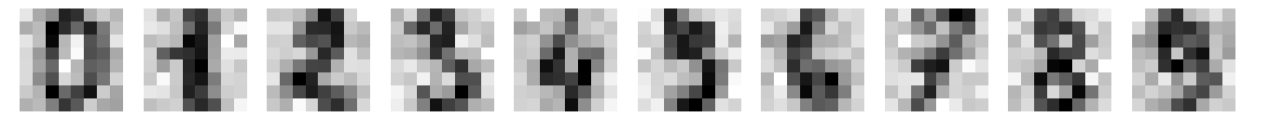
So, clearly we have introduced some noise to the pictures. Now, let’s calculate the principal components and in this case we will calculate as many as we need to keep 70% of the original variance of the data set. This is done with the following code.
pca = PCA(0.70).fit(noisy) pca.n_components_
The output from the last line of code is 13, so to keep 70% of the total variance we need 13 principal components. Super!
Now, we reconstruct the digits by using 13 principal components
components = pca.transform(noisy) filtered = pca.inverse_transform(components)
and some plotting
plt.figure(figsize=(20,2)) for ii in range(1,11): plt.subplot(1,10,ii) plt.imshow(filtered[ii-1].reshape((8,8)),cmap='gray_r') plt.grid() plt.axis('off') plt.show()
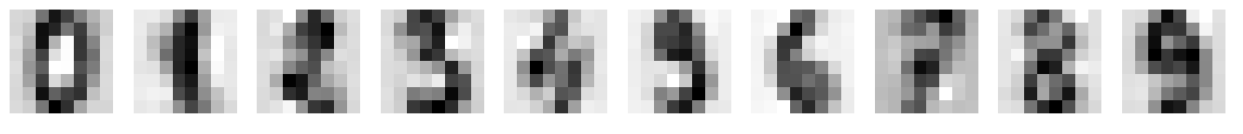
Nice! We can clearly see that we got rid of the noise and the digits look quite ok.
Time to conclude
So, this was the third and (at least for now) the last blog post on the topic of Principal Component Analysis.
Just to do an overall summary, we have seen that a principal component analysis is done by finding directions where we have as large variance as possible for the dataset at hand. We also found out that these directions could be calculated as the eigenvectors of the covariance matrix
In this blog post we used principal component analysis to do dimensionality reduction and noise filtering. For this we used the very convenient PCA class found in scikit learn.
Perhaps in a future blog post we will use the principal component analysis in combination with some classification method, like a Naive Bayes Classifier, to make predictions of which digit an image is showing. Stay túned for that
Well that was all for this time! As always, feel free to contact us at info@gemello.se