Time for a new blog post (I know, it has been some time since the last one...)
This time we are not going to visit the bakery that we spent some time in last year. Insted we are going to visit a small factory that makes "funny" prints for golf balls.
Below we see some examples. The first is from Tiger Woods epic win at the 2005 US Masters and the second one speaks for itself I guess.

Anyhow, Once again you are in charge of the product and your task is to monitor the quality of the prints. One day the boss comes to you (he does not look that happy) and says:
-The print seems to be worse now compared to two months ago, you need to investigate!! Find out what and when things have happened and do it quickly!
Here we go again... (Who cares about these silly printed golf balls anyway...)
So, first of all, it is the boss's perception that things are worse now compared to two months ago, we do not know if this is true. But it seems really important so let's spend some time on this.
What is going on here?
The usual quality control procedure is to take out 100 golf balls each day and report the number of defective prints within the sample. This has been followed but no one has really looked at the results for a long time. So this is perhaps a good place to start. Let's fire up a Jupyter notebook, import and plot the data for the last 60 days of production.
First some standard imports
import numpy as np import matplotlib.pyplot as plt import seaborn as sns import scipy as sp sns.set(context='talk')
and then the data...
defect_vector_golf_balls = np.array([2,7,7,7,2,5,5,4,7,8,1,6,5,7,5,2,10,4,2,11,5,4,12,6,3,6, 4,7,4,4,7,4,5,9,5,11,3,6,3,8,11,9,7,5,10,8,12,9,11,7,9, 6,4,8,12,7,13,9,9,7]) time = np.arange(0,len(defect_vector_golf_balls))
and finally the plot.
plt.figure(figsize=(15,8)) plt.bar(x = time,height=defect_vector_golf_balls,edgecolor='w') plt.xlabel('Days') plt.ylabel('# Defective prints') plt.ylim(0,14) plt.yticks(np.arange(0,14,1)) plt.show()
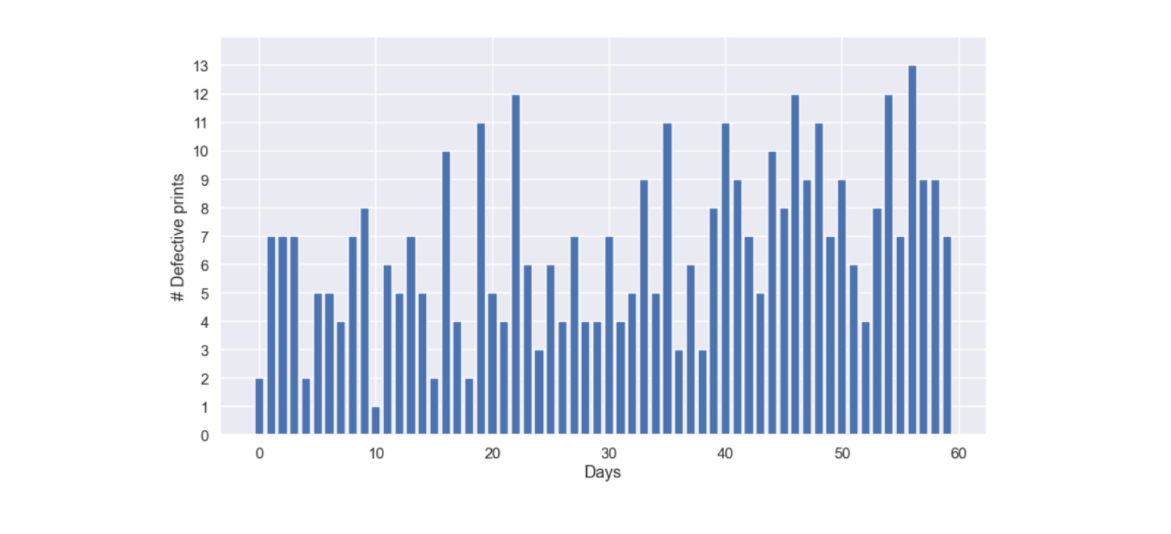
OK, not that easy to say anything but it seems to me that there are some more defective prints in the ending of this time period when compared to the beginning.
So, how to analyse this data then... Since we have looked at Bayesian methods in several blog posts in the past, why not try that out. So what do you need in order to do this analysis then? Well, we have some data so that is a good start. The next step might be to revisit Bayes rule (including the Neon sign that need to be in every presentation about Bayesian stuff)

Or, if we expresset it in terms of Data, \(D\), and Hypothesis, \(H\).
\[ p(H|D) = \frac{p(H) \cdot p(D|H) }{p(D)} \]
As you might remember (if not, check this blog post) the thing to the left is the Posterior \(P(H|D)\) which ultimately is the thing that we are interested in. This can be found by calculating the Likelihood function \(p(D|H)\) together with our prior beliefs about some parameters. We are not going to spend that much time on the thing in the denominator (in the end we will do a normalization so the posterior distribution adds up to 1).
Let's start with the likelihood function. This is where we try to imagine what kind of process that might have generated the data we are looking at. So what do we know then? Well, each sample of 100 golf balls (taken every day) can contain at minimum 0 defective prints and maximum 100 defective prints. So the proportion of defective prints is between 0% and 100%. This feels very much like something that can be described by a binomial distribution. Moreover, the boss said something that the process was better before and this somehow indicates that something has happened during the last two month. So, why not include a parameter, let's call it \(t^*\). The time before \(t^*\) there is one proportion of defective prints, \(p_1\), and after this event there is a different proportion of defective prints, \(p_2\). It might be so that \(p_2\) is larger than \(p_1\), at least that is what the boss is telling you, but we do not know that.
Now that we have decided on what kind of process that we think generated the data it is often a good idea to use this model to generate some simulated data and see if it makes sense. Let's do that for a some different values of \(p_1\) and \(p_2\) as well as \(t^*\). Below is the code that generates some simulated data.
defect_vector = [] sample_size = 100 nr_samples = 60 index_vector = np.arange(0,nr_samples,1) def_rate_befor = 0.06 def_rate_after = 0.03 time_index_change = 20 for ii in range(0,len(index_vector)): if ii<time_index_change: defect_vector.append( np.random.binomial(sample_size,p=def_rate_befor) ) else: defect_vector.append( np.random.binomial(sample_size,p=def_rate_after) ) plt.figure(figsize=(15,8)) plt.bar(x = index_vector,height=defect_vector,edgecolor='w') plt.bar(x = index_vector[time_index_change], height=defect_vector[time_index_change],color='r',edgecolor='w') plt.xlabel('Days') plt.ylabel('# Defective prints') plt.title('# Defective prints, p1=0.06, p2=0.03, t_star=20') plt.show()
And here are two different plots
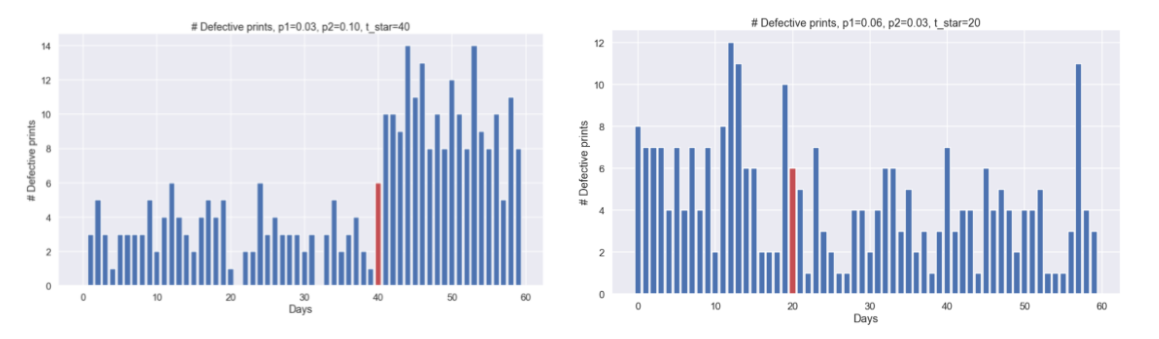
Well, this does not look too bad. At least to me, this seems like a reasonable model that could have generated the observed data.
So, let's return to the original task of finding out the likelihood function. Note that we have made a model of the process that (we think) have generated the data we can calculate the likelihood function \(p(D|H)\), i.e how likely is it to see the observed data given a specific set of parameters \(H\). The model has three different parameters:
- the proportion of defective prints before the "event", \(p_1\)
- the proportion of defective prints after the "event", \(p_2\)
- the time when the "event" occurred, \(t^*\)
and to find the likelihood \(p(D|H)\) we just multiply the likelihood for all data points. It would look something like this (using the probability mass function for the binomial distribution from the \(scipy.stats\) module)
p1=0.2 p2=0.2 t_star = 35 likelihood = (np.prod(sp.stats.binom.pmf(defect_vector_golf_balls[:t_star],n=sample_size,p=p1))* np.prod(sp.stats.binom.pmf(defect_vector_golf_balls[t_star:],n=sample_size,p=p2)) )*1e40
The large number in the end is just to scale up the values (if not the numbers would be so small so we would lose accuracy).
So far so good! The next thing we need to deal with is the prior distributions of the parameters for our model. As stated above, we have three different parameters for our model and we need to assign some priors to all of them. In this example we are going to use a sort of uninformed prior, i.e. we do not have any super strong belief about the values of the different parameters. The only thing we are going to assume is that the proportion of defective prints is not above 30% because this has never been observed before according to the historical data. So to make it simple we are going to assume that the prior distribution of both \(p_1\) and \(p_2\) is a uniform distribution between 0 and 0.3, outside of this it is 0. Moreover we are going to assume that the prior distribution of \(t^*\) is a uniform distribution between 0 and 60 i.e. it is equally likely that the event happened on any day of the studied intervall.
So, now we have decided on a model and defined the likelihood function and we have the prior distributions for the parameters that we would like to estimate. This means that we are ready to do some estimation using the observed data, awsome!
The Gridding Method
We are going to do all computations using a gridding method that we have used in all the previous blog posts about Bayesian statistics. This time we have three parameters so we will stack three different for loops on top of eachother and for each combination of parameters calculate the likelihood function and multiply if with the values of the prior distributions. Since the prior distributions are uniform we can use any constant value for the priors, remember that we are going to normalize the whole posterior as a final step to ensure that the sum is 1. So, let's put it into some code!
P_1 = np.arange(0,0.3,0.001) P_2 = np.arange(0,0.3,0.001) prior_p1 = 1 prior_p2 = 1 prior_t_star = 1 Posterior = [] Grid_t_star = [] Grid_p1 = [] Grid_p2 = [] for p1 in P_1: for p2 in P_2: for t_star in index_vector: like = (np.prod(sp.stats.binom.pmf(defect_vector_golf_balls[:t_star],n=sample_size,p=p1))* np.prod(sp.stats.binom.pmf(defect_vector_golf_balls[t_star:],n=sample_size,p=p2)) )*1e40 Posterior.append(like * prior_p1 * prior_p2 * prior_t_star ) Grid_p1.append(p1) Grid_p2.append(p2) Grid_t_star.append(t_star) Posterior = np.array(Posterior) / np.sum(np.array(Posterior)) Grid_p1 = np.array(Grid_p1) Grid_p2 = np.array(Grid_p2) Grid_t_star = np.array(Grid_t_star)
So, what we have now is the value of the posterior distribution for each combination of the three involved parameters. This is sort of a three dimensional thing since it has three parameters but in order to get some understanding of what the posterior looks like let's compute the marginal distribution for each of the parameters.
marginal_t_star = [] for ii in index_vector: marginal_t_star.append(np.sum(Posterior[Grid_t_star==ii])) marginal_p1 = [] marginal_p2 = [] for p1 in P_1: marginal_p1.append(np.sum(Posterior[Grid_p1==p1])) for p2 in P_2: marginal_p2.append(np.sum(Posterior[Grid_p2==p2]))
Now, let's have a look at them! Why don't we start with the marginal distribution of the \(t^*\) parameter i.e. when in time did the "event" occur?
plt.figure(figsize=(10,8)) plt.bar(x=index_vector,height=marginal_t_star,color='g',edgecolor='k') plt.xlabel('Days') plt.title('Marginal distribution of t*') plt.show()
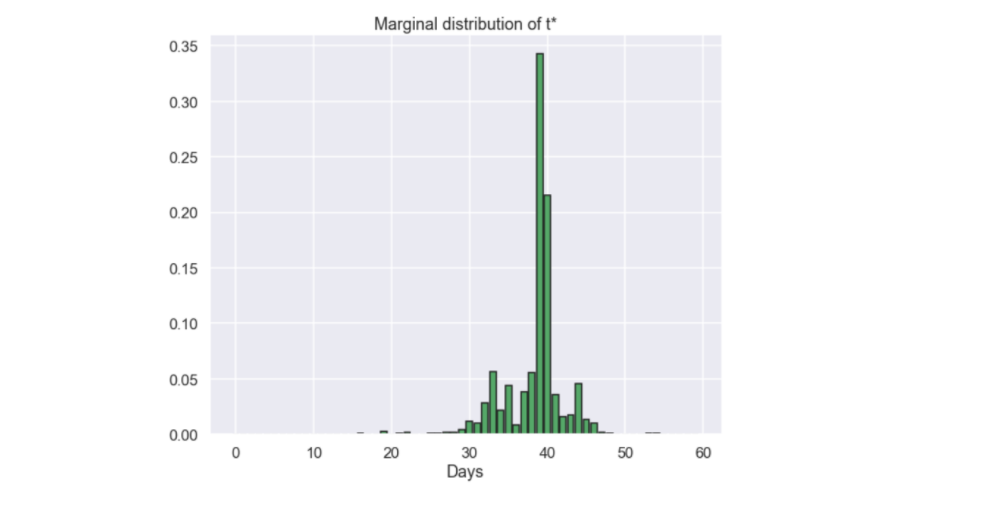
Nice! This looks super interesting! It seems that the event occurred around day 40 in the data set. It also looks like the event happened quite abruptly since the values of the marginal distribution around 40 are really high compared to the others. if the "event" happened slowly the marginal distribution of \(t^*\) would probably be much more spread out.
Let's continue to have a look at the marginal distributions of \(p_1\) and \(p_2\) and see if we can spot any difference between them.
plt.figure(figsize=(10,8)) plt.plot(P_1,marginal_p1,'r',lw=3, label='p1' ) plt.fill_between(P_1,marginal_p1,color='r',alpha=0.2) plt.plot(P_2,marginal_p2,'b',lw=3, label='p2' ) plt.fill_between(P_2,marginal_p2,color='b',alpha=0.2) plt.xlim(0.00,0.25) plt.xlabel('Proportion of defective prints') plt.title('Marginal distribution of p1 & p2') plt.legend() plt.show()
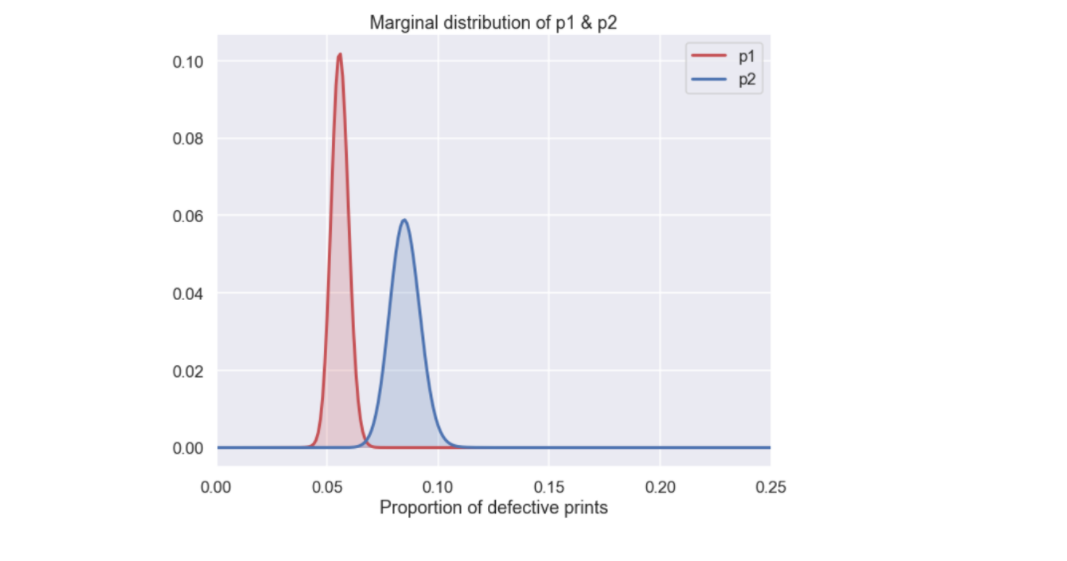
So, it looks like the boss was right. The posterior distribution of the parameter \(p_2\) i.e. the proportion of defective prints after the event is indeed higher than the proportion of defective pints before the event, \(p_1\). To be more precise it seems like the most probable value of \(p_1\) is just above 5% and for \(p_2\) it is more like 8%. One more thin: Since there is not the much overlap between the marginal distributions of \(p_1\) and \(p_2\) we can be quite certain that the proportion of defective prints actually has gotten worse.
Time to conclude
So, one more blog post on Bayesian statistics has come to its end.
I think that this example really shows the flexibility of a Bayesian approach to a problem like this since it would be hard to find this out by using some "out of the box" statistical test. If you would try the code out by yourself you would find that the runtime for the cell that calculates the posterior distribution is really long. This is a drawback of the gridding algorithm when you have many parameters. In this case we had three and it was sort of manageable but if you had several more, the gridding algorithm would no longer be a feasible option.
As always please feel free to contact us at info@gemello.se.
So, until the next time, Fore!