It is time to have a look at yet another classic example in probability theory but with a somewhat different focus. This is a story about the famous french mathematician Henrie Poincaré who lived between 1854 and 1912. The story goes (although probably made up) like this
Every morning Poincaré went to the local bakery and bought a bread labeled with a weight of 1000 g. When he got home he weighed the bread and noted the weight. After one year he made a summary of all the data he had collected.
If he would have made a histogram it would look something like this
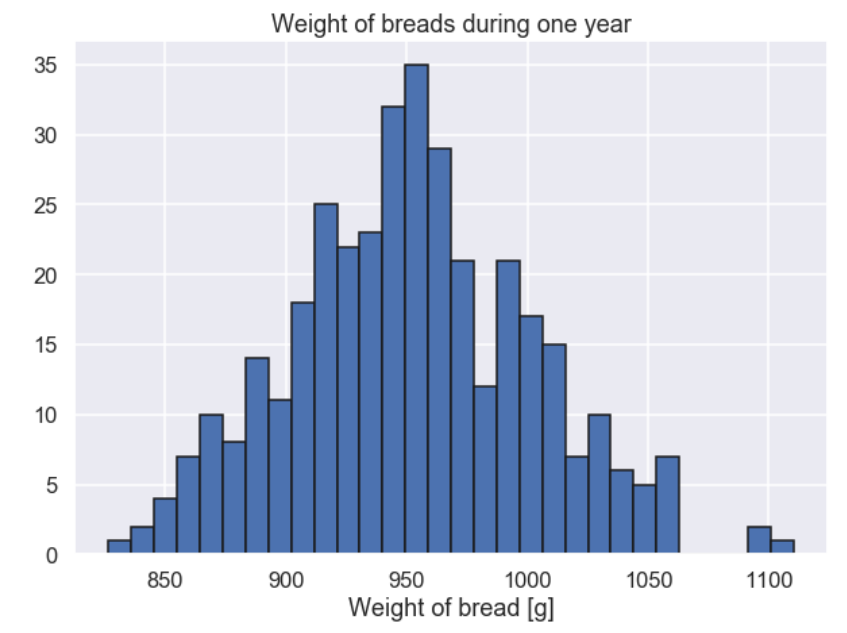
After seeing this histogram he went to the (bakery)police since obviously the baker did not produce breads with a weight of 1000 g. The police gave the baker a warning and the baker promised to make some changes.
This is where this blog post starts since I would like to tell the not so often told story of the baker.
After receiving the warning the baker was kind of upset:
That *** Poincarrot or whatever his name was.... thinking he is so smart... well I know a thing or two about (computational) statistics my self..
said the baker and fired up his post industrial jupyter notebook.
I know that the current production of bread is very well described by a normal distribution with a mean value of 950g and a standard deviation of 50g and I'm not changing that since it is way too expensive. What if I every morning weigh all of the produced breads (approximately 150) and pick out the heaviest one and give it to Poincaré... then he can't complain... I'm so smart... I will make a simulation of this and see what the mean value might be..
The steps of such a simulation will be:
- For every day (during a whole year) record the weight of all the produced breads, pick out the heaviest one and give it to Poincaré.
- At the end of the year calculate the mean value of all the 365 bread that Poincaré would have gotten.
Let's write that in code! (first some imports)


OK, a mean value of 1082 g not to bad! If we run the same code one more time we would expect to get a differnt answer and in this case it was 1083 g. So, currently we have two values way above 1000 g so this seems promising! To get more confidence lets run the same code a large number of times, say 100 000, and investigate how the mean value might vary. To do this we just put a loop on top of the same code and store the mean values in a list

And here is a plot
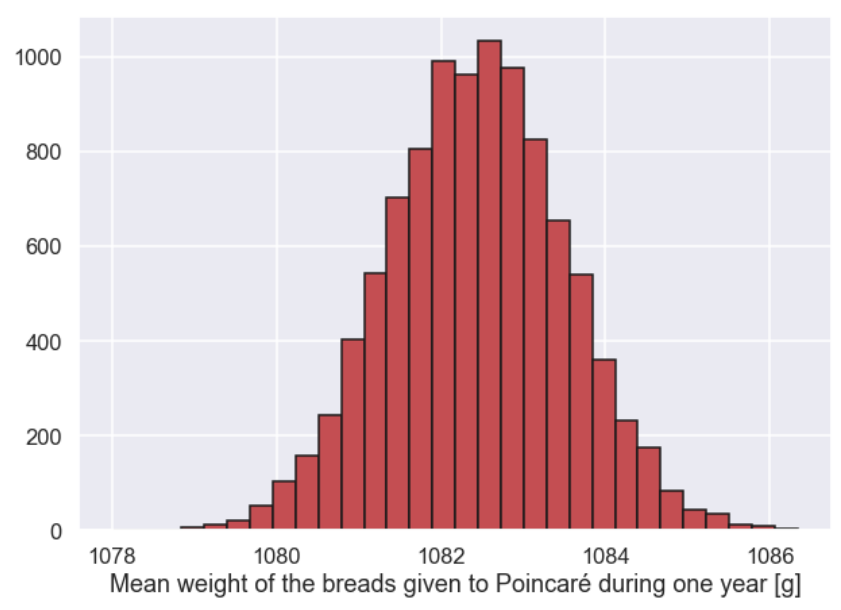
After seeing the graph the baker thinks:
Allright!!! That is way above 1000g! Now that Poincaré guy can impossibly complain! Just to be sure, lets plot the CDF of the weights of the breads given to Poincaré during one year
Ok, a Cumulative Distribution Function (CDF) represents the proportion of measured values that are below as certain value. Let us make a function that takes the data as argument and plot the CDF. Just for the fun of it, let us also include the cdf of a normal distribution with the mean and standard deviation of the data passed to the function.

And when looking at data from a randomly selected year the baker gets this graph
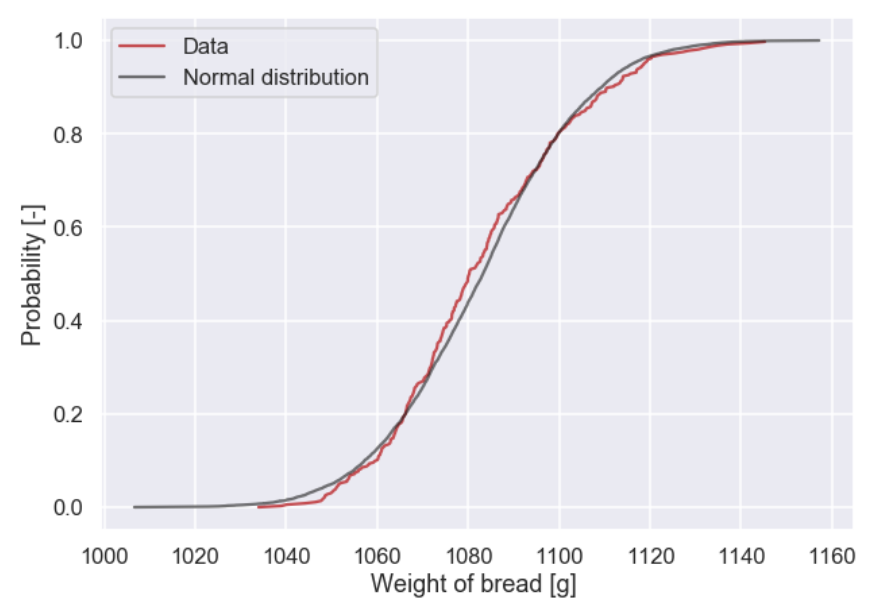
And the baker thinks:
What?? That does not look like a normal distribution... it is sort of skewed. If Poincaré would see this he will get suspicious... Perhaps there is a way. Since I am giving him the heaviest bread of the whole days production, 150 breads, the mean value is way above 1000 g. What if I only measure a smaller number of the daily production, say N breads, and give him the heaviest one. I can then investigate wich N that will give a mean weight of approx 1000 g
Lets do this! Let's try an N ranging from 2 to 15 breads. For every N do a high number of simulation for one years production. For each N we will end up with a histogram similar to the one above but in order to make the visualization of different N a bit easier we just store the mean value.

And the plot
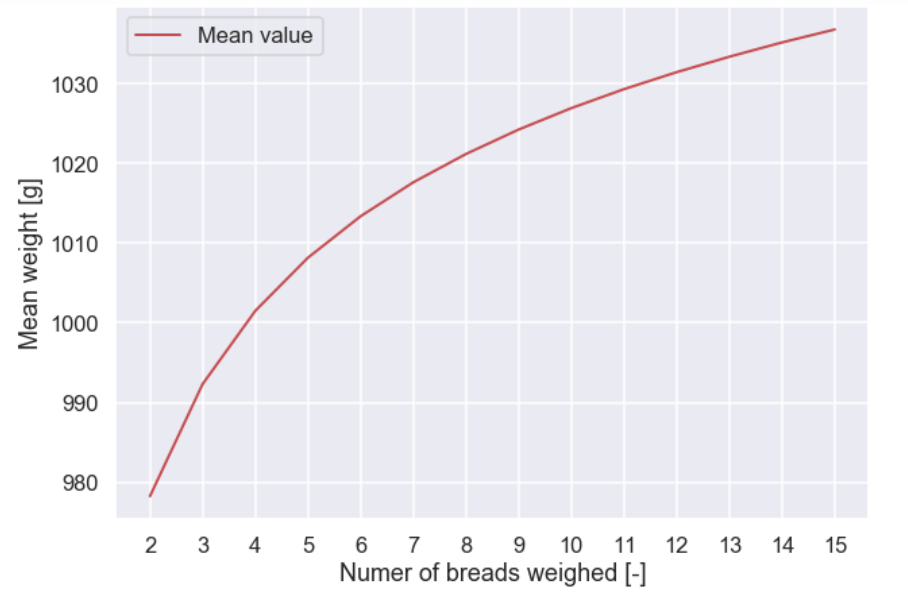
And the baker thinks:
OK, I can get away with just giving him the heaviest out of 4 randomly selected breads from a daily production, sweet!! Much less work for me too, compared to having to measure the whole daily production, even better!! I suppose that the problem with a skewed distribution that I got previously must be much better... but is it good enough?? I will make a simulation and check...
To investigate this we need a way to quantify the skewness of a distribution, luckily there are several definitions of skewness, but let try this one
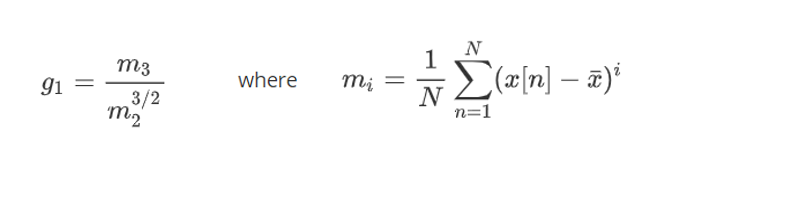
The calculation of the skewness according to the definition above is directly available from the scipy stats package..
So lets simulate one year of giving Poincaré the heaviest out of four measured breads (N=4) and calculate the skewness according to the definition above. Lets do this a large number of times to capture the sampling variation.

And the plot
The baker thinks:
Ok.. the most common value is around 0.25 ... there are some values below zero... Hard to tell what this means.. I probably should make a simulation of what the data would look like if the data came from a normal distribution and compare..
To estimate this let's make a new simulation that answer the question: If the data came from a normal distribution, within what range would we expect the values of the skewness to be?

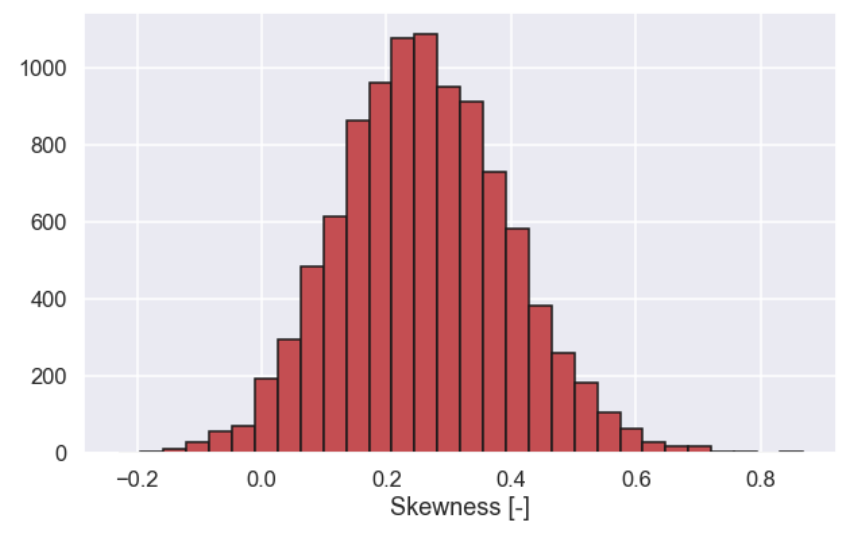
And the plot
The baker thinks:
This is what the skewness would look like if the data came from a normal distribution. The most common value is approximately 0 (which is expected) and values above 0.20 are unusual. Let's try to find the value that only 5% of the samples are above.
This can be done with the numpy function percentile

OK you can say that if the data would come from a normal distribution, skewness values above 0.21 would be so unlikely that you would say that this can not have happened by chance. How often would this happen in the case where Poincaré gets the heaviest bread out of 4??

And the baker conclude:
Now I think I have the full picture. If I (for every day during a whole year) give Poincaré the heaviest bread out of 4 randomly selected ones he will most probably get a mean value of the weight for the whole year that is very close to 1000 g. That is good. The not so good thing is that if he calculates that skewness of the data, there is a risk of almost 65% that he will get a value that is so high that it would indicate that the data did not come from a normal distribution. He could then probably claim that I have cheated (again) and not changed the recipe of the bread... not so good ... but there is a 35% chance that he can not claim this... so let's give it a try!!
Time to conclude
So there you have it, the not so often told story of the baker. In this blog post we have focused on the estimation of risks given that we know the process parameters (in this case the mean and the standard variation). The problem that Poincaré would be faced with is called "statistical inference". In his case he do not know the process parameters and his task would be to estimate them (or at least to say something about them). We sort of did this in the very last section of the blog post. However, the plan is to write a blog post dedicated to statistical inference in a not to distant future, so stay tuned!
Well that is all for now! If you have comments or other things you would like us to know please send an email to info@gemello.se